Mentors
- Raghuram Kannan
- Vasanth M
Members
- Omkar Patil
- Vishal Marwade
- Abhiraj
- Kaushik Srivastava
Table of Contents
Aim
To develop deep learning models to generate images for given audio input using speech to text and then text to image .
Introduction
In this project we attempt to translate the speech signals into image signals in two steps. The speech signal is converted into text with the help of Automatic speech recognition (ASR) and then high-quality images are generated from the text descriptions by using StackGAN.
Step-1 Speech to Text
Automatic speech recognition (ASR) consists of transcribing audio speech segments into text. ASR can be treated as a sequence-to-sequence problem, where the audio can be represented as a sequence of feature vectors and the text as a sequence of characters, words, or subword tokens.
The Dataset we are using is the LJSpeech dataset from the LibriVox project. It consists of short audio clips of a single speaker reading passages from 7 non-fiction books. Our model is similar to the original Transformer (both encoder and decoder) as proposed in the paper, “Attention is All You Need”.
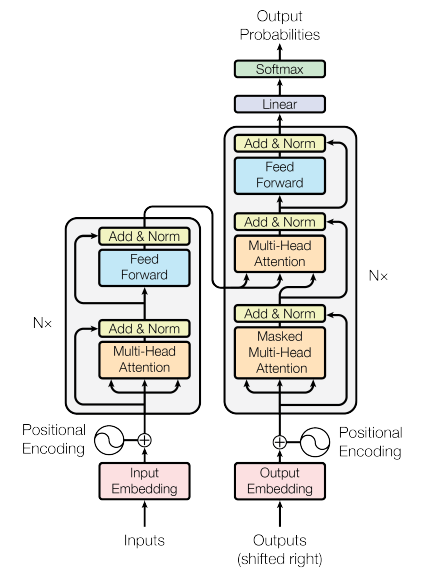
Transformer Model Architecture
Transformer model architecture follows seq-to-seq model using encoder-decoder structure along with multi head attention. It takes input and gives output t in a parallel manner. Hence increasing the efficiency compared to conventional RNN model. This model was introduced in “Attention is all you need” paper in 2017 and since then this architecture has been the first choice for modelling speech recognition.
Training Result
Following word error rate(wer) was achieved after training speech to text model.

Step-2 Text to Image
Create 3 folders (test, weights,results_stage2) in your current working directory
- weights (your model weights will be saved here)
- test (generated images from our stage I GAN)
- results_stage2 (generated images from stage II fo GAN)
About Dataset
Dataset Name: CUB_200_2011
Download from : https://data.caltech.edu/records/65de6-vp158
Text Embedding Model
Download char-CNN-RNN text embeddings for birds from : https://github.com/hanzhanggit/StackGAN
- char-CNN-RNN-embeddings.pickle — Dataframe for the pre-trained embeddings of the text.
- filenames.pickle — Dataframe containing the filenames of the images.
- class_info.pickle — Dataframe containing the info of classes for each image.
Architecture
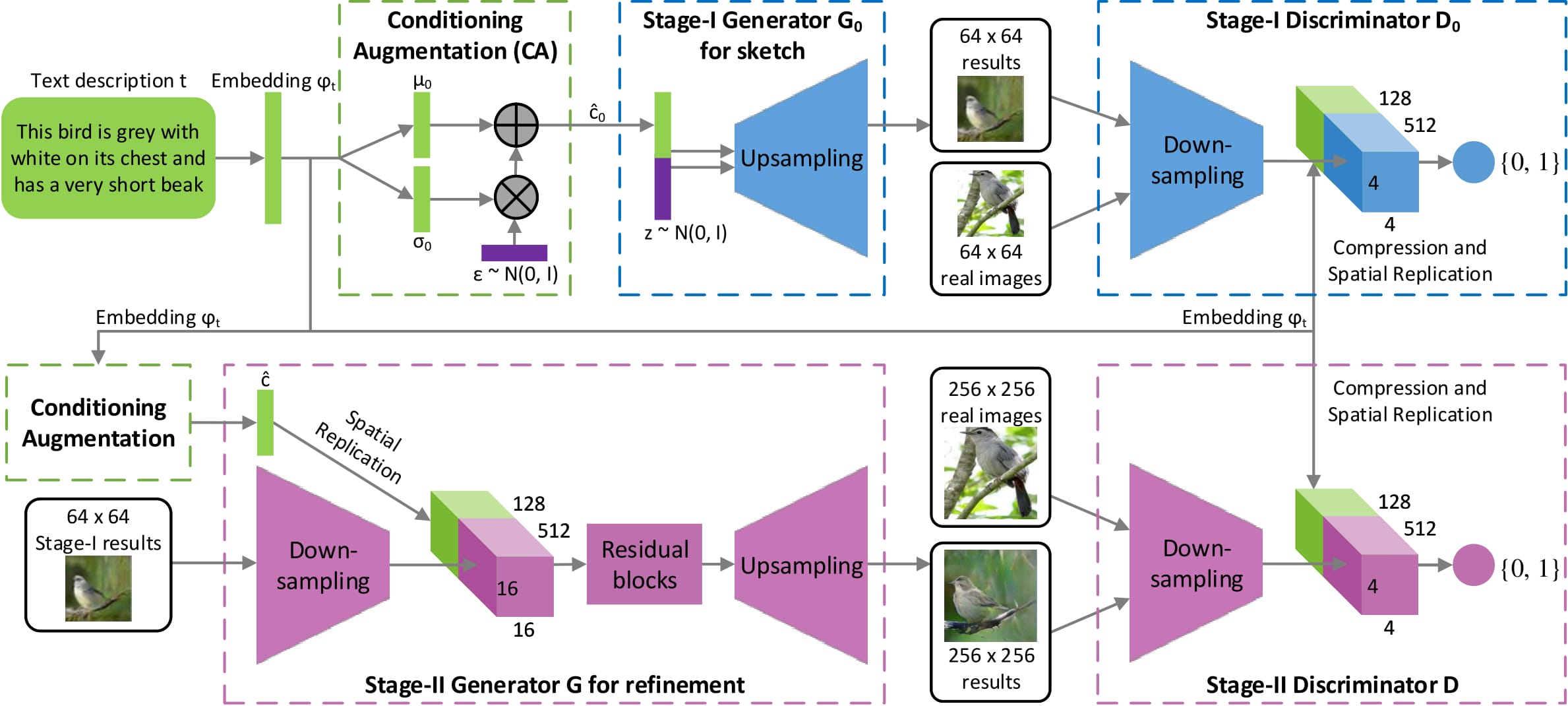
- Stage 1
Generator :
The text-to- image model learns from the features that capture important visual details. Based on the visual details described in the text, it generates images which look real.
The text description is converted to a text embedding(vector of real numbers of fixed length) using Word2Vec pretrained model. The embedded text is concatenated with a random noise vector and is input to the generator. This generator generates a fake image as per the text description. The generated fake images along with the text description is input to the discriminator. The discriminator classifies whether the sample is fake or real. In stage-I GAN, the generator generates a low resolution 64*64 RGB image. This image captures low level features like color and shape of the object.
- Steps in stage 1
- Text Encoder Network
- Text description to a 1024 dimensional text embedding
- Learning Deep Representations of Fine-Grained Visual Descriptions Arxiv Link
- Conditioning Augmentation Network
- Adds randomness to the network
- Produces more image-text pairs
- Generator Network
- Discriminator Network
- Embedding Compressor Network
- Outputs a 64x64 image
- Text Encoder Network
- Steps in stage 1
- Stage 2
Discriminator:
The output images of the stage-I generator and the embedded noise(vector) become the inputs to the stage-II generator. The sage-II generator tries to refine the image of stage-I generator and provides a high resolution $256*256$ RGB image. The high level features of the text descriptions are generated here. The image generated by this generator along with text embeddings is input to the discriminator similar to stage-I discriminator. This acts as a classifier differentiating fake and real images.
Since image generation takes place in 2 stages, the model generates high resolution images.
- Steps in stage 2
- Text Encoder Network
- Conditioning Augmentation Network
- Generator Network
- Discriminator Network
- Embedding Compressor Network
- Outputs a 256x256 image
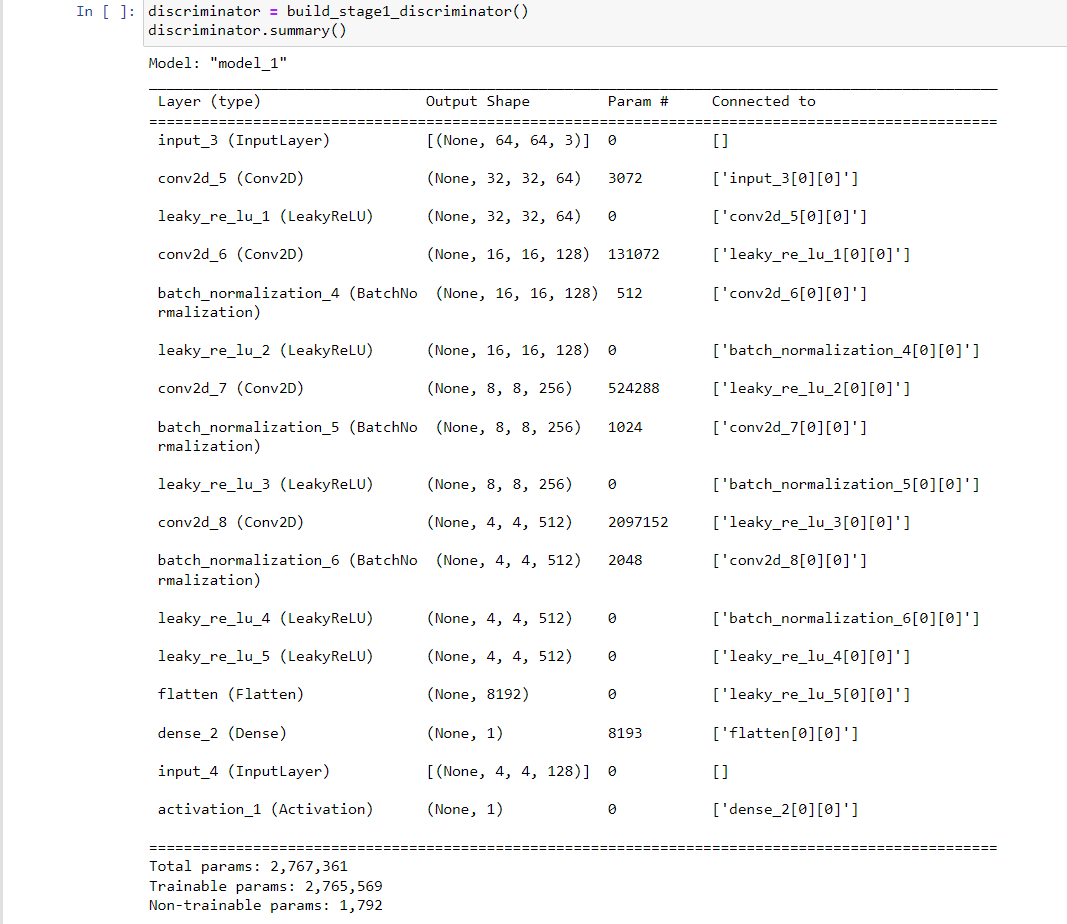
- Steps in stage 2
Conclusion
- Speech to text model was trained to achieve considerable word error rate for given size of dataset. Text to Image model also has been able to achieve desirable results.
References
- Attention is All You Need [Arxiv Link]
- Very Deep Self-Attention Networks for End-to-End Speech Recognition [Arxiv Link]
- Speech-Transformer [IEEE Xplore]
- StackGAN: Text to photo-realistic image synthesis [Arxiv Link]