Team Members
- Adithya Jayan
- Anirudh Aatresh
- Deeksha MS
- Nikhil Nair
- Suraj Kulkarni
Abstract
Sonic Eye is aimed at providing visual perception to the blind with the help of Signal Processing and Artificial Intelligence-based models. Conversion of image to audio through scalar 2-D to the time-frequency domain was successfully done with minimum loss of information. The efficiency was proved using a simple kNN algorithm by comparing the classification of sample datasets (MNIST, CIFAR) by feeding the image directly and the audio generated through our method. This method requires sufficient training hours for the blind person to get acquainted with the system. Alternatively, a deep learning-based model was developed for object detection.
Objectives
To develop an artificial intelligence-based model to aid the blind in visual perception.
Methodology
Image to Audio Conversion
- vOICe algorithm:
For this algorithm, we employed a nonparametric approach. To map information present in an image to sound, we followed the approach commonly known as vOICe. To understand this method, consider an image I of size 100 x 100 x 1 (in the format of width x height x channels). We take each column of I, and consider that to be a 1D sequence of weights. Each weight has a corresponding tone or frequency of sound associated with it. So to obtain the sound corresponding to the 1D sequence, we add the weighted combination of these tones, such that they are weighted by the 1D sequence(or column) of the image I. This audio clip is played for a fixed amount of time t seconds. This is repeated for the consecutive columns in the image, maintaining the column order. Hence, if the image has n columns, the total length of the mapped audio file of the image will be nt seconds. In other words, we are converting the image into a sort of spectrogram. To give a higher sense of perception, we have ensured that this audio clip is played in a stereo fashion, that is, the leftmost column causes the entire sound to be directed to the left and same to the right. In between, we mix both left and right channels.
For practical use, it is crucial to note that this technique requires practice by the user. We have referred to many sources that state that most of the visually impaired have a heightened sense of sound perception. We therefore hope that this will be an easier task for the visually impaired to learn. - kNN verification:
To build a good ablation study and prove no loss in data during conversion, we have also performed object classification using the k-nearest neighbors algorithm. To understand this verification study, consider 2 classes of images, say images of tables (class 1), and images of dogs (class 2). We compared the classification performance between feeding the image directly as input (after vectorizing it) to the model versus feeding the audio clip of the image obtained using the vOICe algorithm.
CNN Model for Object Detection
In order to overcome the subjectivity in the vOICe algorithm, we incorporated an artificial intelligence-based model. A deep convolutional network with structure as depicted in the image below was loaded with pre-trained weights from the state-of-art YOLOv3 model. The pre-processing and post-processing were coded on the python3 platform to give the final result of bounding rectangles and their respective object class. ImageNet data samples were used for this experimentation.
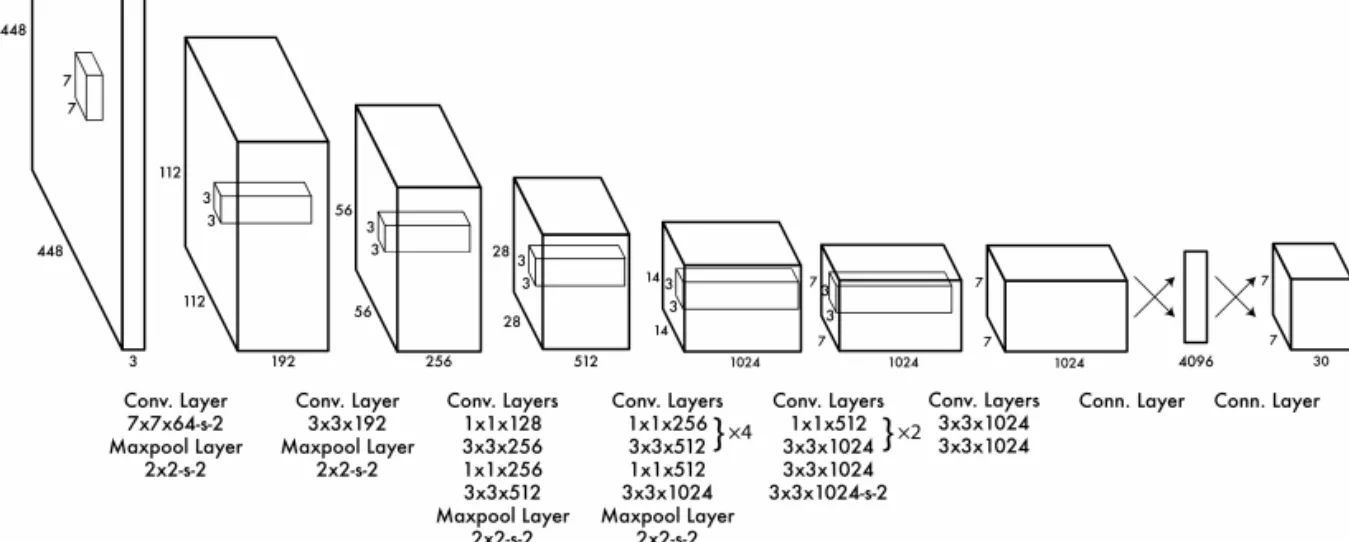
Results
- vOICe:
In the audio generated for the image of ‘A’, you can notice a gradually increasing frequency and then decreasing accompanied by certain beats caused by the presence of multiple frequencies. These are the kind of unique features that the person needs to identify and utilize.
Converted audio
- kNN results:
From this verification study, we were able to show that both methods of input are giving a similar performance and that there is no loss in information during the conversion. This step is vital to consider the vOICe algorithm to be a good contender for an efficient image to audio conversion algorithm. - Object detection:
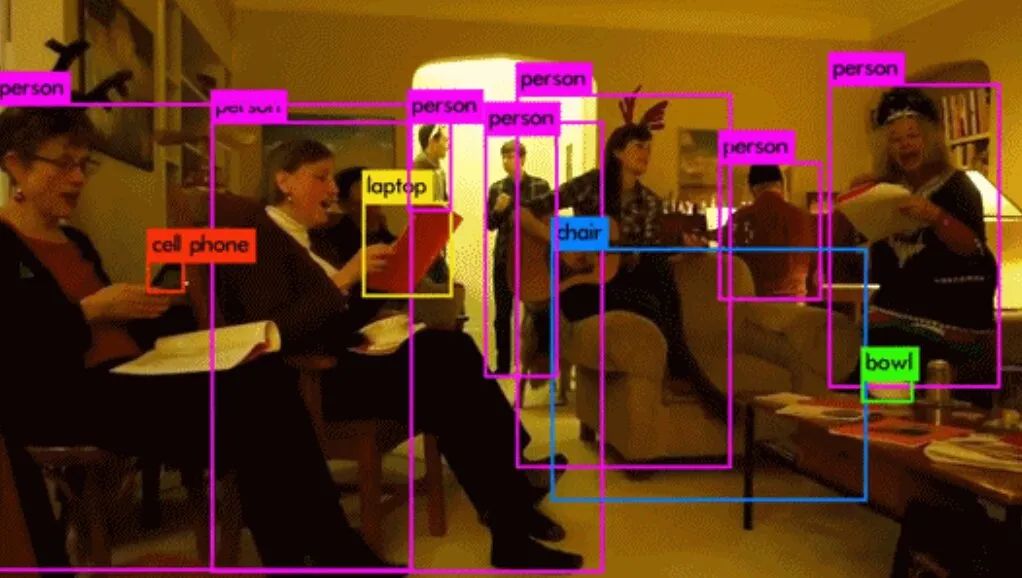
Application and Future Work
This model can be extremely useful to the visually impaired to get an essence of the world. While the first model, image to audio conversion, demands strenuous training of the blind people to get adjusted, the deep learning-based model is more efficient and user-friendly. But this also restricts the object domain to a finite number in contrast to the robustness and unrestricted application scenario in the first method.
In the future, we hope to incorporate image captioning and audio description into the YOLO model.
References
- https://www.seeingwithsound.com/projects.htm
- J. Redmon, S. Divvala, R. Girshick and A. Farhadi, “You Only Look Once: Unified, Real-Time Object Detection,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016, pp. 779-788, doi: 10.1109/CVPR.2016.91.
- Kedar Potdar, Chinmay D. Pai, Sukrut Akolkar, “A Convolutional Neural Network based Live Object Recognition System as Blind Aid”, arXiv 1811.10399 2018