Mentors
- Nishant Nayak
- Harshwardan Singh Rathore
Mentees
- Sana Azmiya
- Madhav Kumar
- Darshan S
- Akhilesh P
Introduction
Optical character recognition or optical character reader is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo or from subtitle text superimposed on an image.
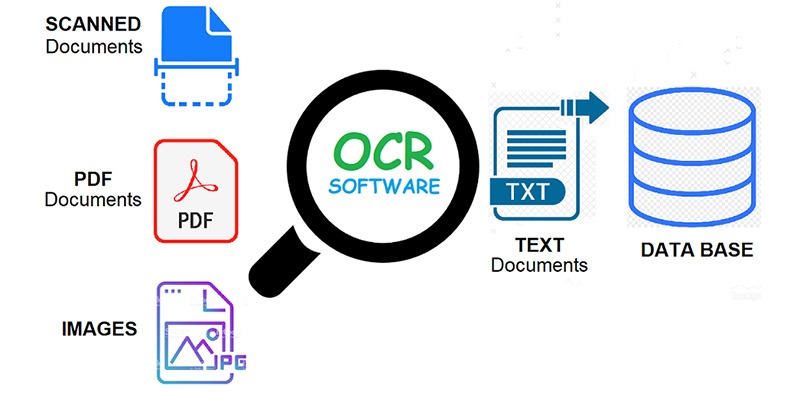
A popular use case of OCR is invoice capture. With the combination of OCR and other AI techniques, companies can easily extract data from invoices. In the invoice capturing process, OCR is used to transfer data from printed invoices to digital systems. As a result, invoices can be automatically processed faster.
The objective of OCR is to achieve modification or conversion of any form of text or text-containing documents such as handwritten text, printed or scanned text images, into an editable digital format for deeper and further processing. Therefore, OCR enables a machine to automatically recognize text in such documents.
Convolutional Neural Networks for OCR
CNN or Convnet stands for Convolution Neural Networks. It basically is a Deep Learning algorithm which takes an input image, tunes the weights and biases to predict the different features of the image and classify them. It consists of five basic computational steps as the layers of the network.
- Convolution Layer
- Activation Function
- Pooling Layer
- Padding
- Fully-Connected Layer
Convolution Layer
The images consist of pixels and are stored in forms of matrices. The convolution layers consist of filters in the form of 3x3x1(or 3 for RGB images) or 5x5x1 square matrices containing weights. These filters superpose on the image matrix and do matrix multiplication to obtain feature maps. These feature maps contain the different characteristics of the image. We can use more than one filter on the same image to obtain different types of feature maps. For RGB images we have three channel filters which in turn form feature maps in the form of 2D matrices.
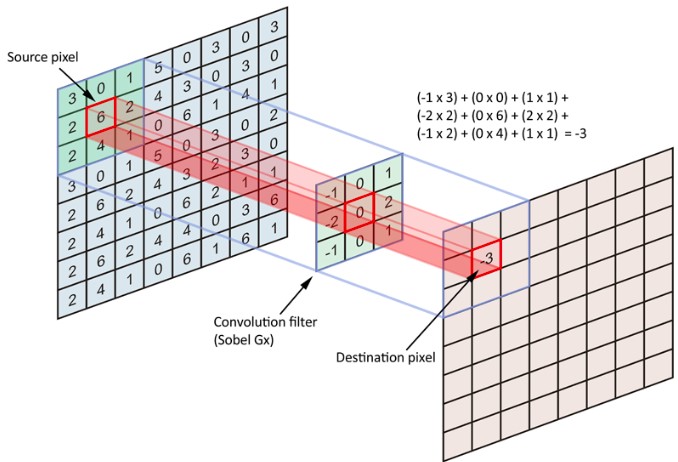
Activation Functions
These functions add non-linearity to the model to better predict complex features in the images. The most commonly used activation function is ReLU activation function. It maps all the negative numbers to zero and the positive numbers from 0 to infinity.
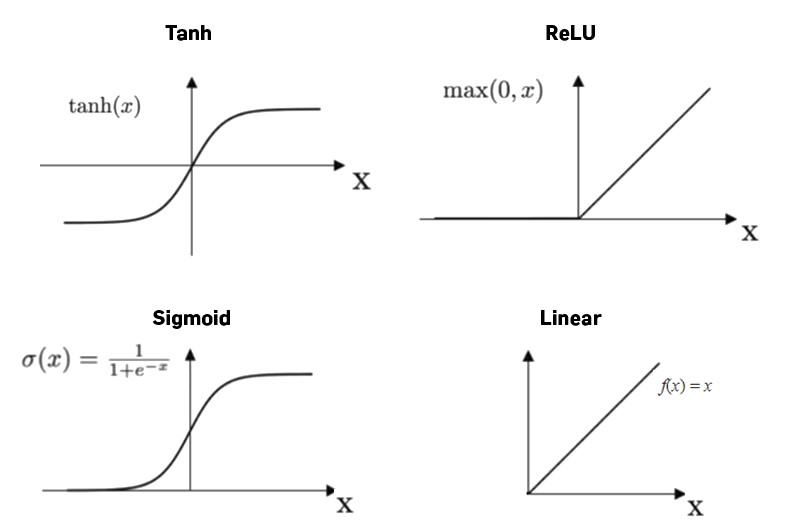
Pooling Layer
This layer reduces the spatial size of Convolved Feature to reduce the computational power required to process the data through dimensionality reduction without missing out the important features of the image.
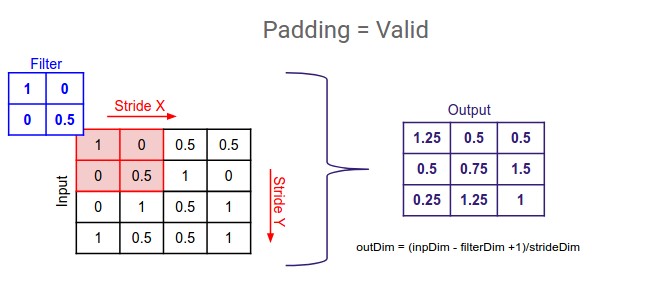
Padding
It refers to the process of adding rows and columns around the image matrix. It increases the number of mapping of the corner pixels of the original images and also does dimensional enhancement to make up for the dimensional reduction due to convolution layers.
Fully Connected Layer
After doing the convolutional operations, the 2D matrices are flattened to form a deeply connected neural network. It contains different activation functions to add non-linearity to the model and decrease the losses.
Dataset Used
MNIST Dataset
The MNIST (Modified National Institute of Standards and Technology) database, an extension of the NIST database, is a low-complexity data collection of handwritten digits used to train and test various supervised machine learning algorithms. The database contains 70,000 28x28 black and white images representing the digits zero through nine. The data is split into two subsets, with 60,000 images belonging to the training set and 10,000 images belonging to the testing set. The load_data function by Keras is used to load this dataset.

A-Z Handwritten Dataset
This database contains 370000+ 28x28 gray level images of letters from A to Z. The Kaggle API is used to download the A-Z handwritten dataset. In order to do this, an API key has to be generated and uploaded to the Google Colab notebook. The dataset is then loaded into a pandas DataFrame.

The A-Z handwritten dataset is split into train and test sets. The MNIST digits dataset is already split into train and test sets and hence is left as it is.
The MNIST digits dataset is reshaped to a set of 784 dimensional vectors. The data is then scaled using the Standard Scaler provided by scikit-learn.
The target variables from the A-Z alphabets dataset is incremented by 10 so that labels 0-9 correspond to the digits from 0-9 and labels 10-35 correspond to the alphabets from A-Z. The MNIST digits dataset and A-Z handwritten dataset is then compiled into a single dataset. One hot encoding is applied to the target variable in order to align it with the output of the CNN model.
The combined dataset is later uploaded to Kaggle, which might prove useful to others with similar projects.
Models Used
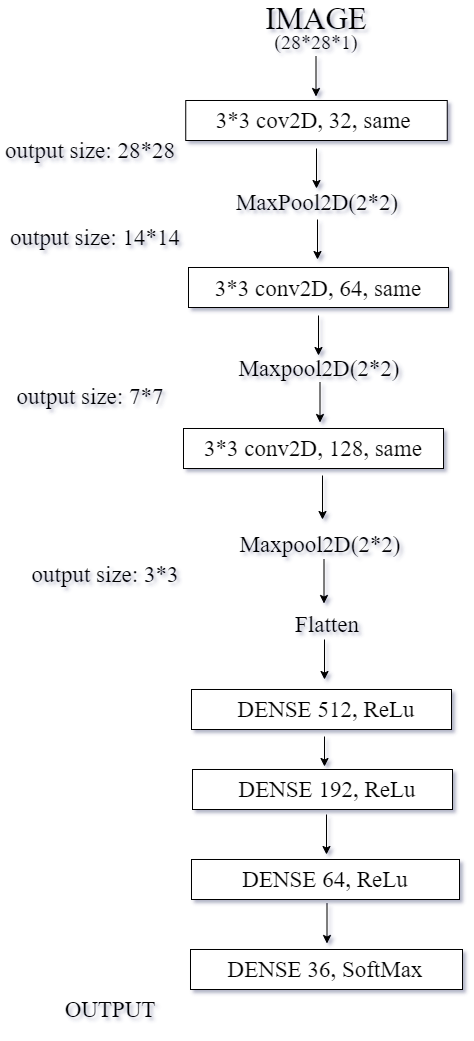
The model used contains 3 Convolutional layers followed by 4 Dense layers. In the first layer, there are 32 filters of size 3x3 with ReLU activation function with same padding followed by MaxPool layer of 2x2. In the second layer, the number of filters is increased to 64 with everything else is same as layer 1. In the third layer, the number of filters is further increased to 128. These are followed by 4 dense layers, the first three of which have ReLU activation function and the last one having softmax function which actually gives the probability of the image being in different classes of numbers and alphabets.
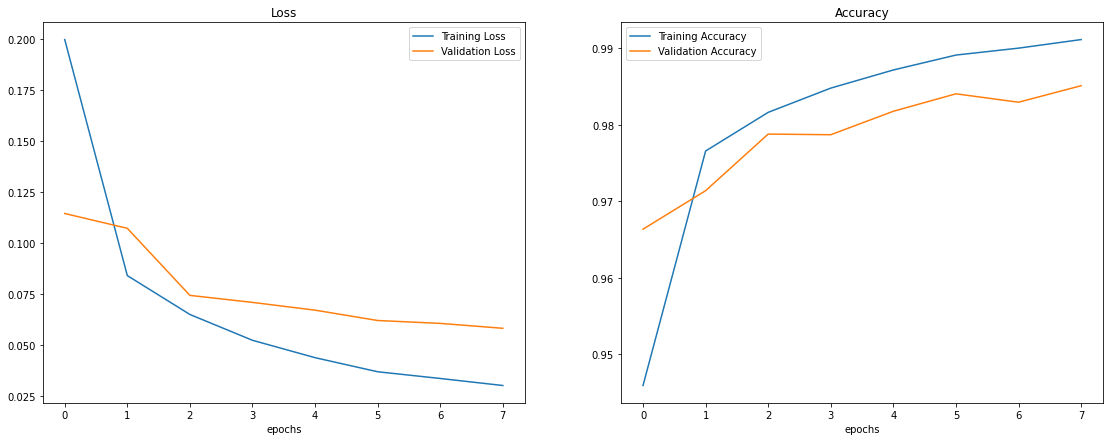
Upon training the model for 8 epochs with a batch size of 128, using the Adam optimizer to optimize the learning rate, we were able to obtain 99.18% accuracy on the training data and a validation accuracy of 98.51% accuracy. The values of the loss function and accuracy vs number of epochs are plotted below:
Outcomes
We obtained an image of handwritten characters from the internet to test how accurately our model can predict on real world data. We used the OpenCV Python library to extract each individual character from the image, by finding the contours and reshaping each character to a 28x28 image. We then ran these examples through the CNN model and wrote the predicted results back on to the source image. The results are shown below:

We can see that the model seems to be predicting most of the characters correctly, but it is still making a significant number of mistakes. Of the 40 characters that the model predicted, only 24 characters were predicted correctly. This could be due to the fact that the model used is too simple, and with a more complex model architecture we can obtain more accurate predictions. Another possible reason is that the training examples need to be more diverse in order to capture many different types of handwriting.
Conclusion
We have discussed what OCR is and what its objectives and applications are. Then, we discussed how CNNs are used in OCR. We discussed Convolution Layers, filters, feature maps and activation functions. We also discussed Pooling Layer, Padding, Fully-Connected Layer, etc. Then we talked about the A-Z alphabets and MNIST datasets that we have used and how we preprocessed the dataset. We also combined these datasets and uploaded the combined dataset to Kaggle so that other people can use it. After that we discussed the model architecture. Our model has 3 Convolutional and MaxPool layers followed by a Flattening layer and 4 Dense layers. We also discussed the accuracy of our model on training and validation sets. Finally, we mentioned some of the drawbacks our model faces when predicting on real world data.
All our work for the project has been documented in this GitHub Repository.