Mentors
- Rakshit P
- K Dharmick Sai
Members
- Anirudh Prabhakaran
Real Time Style Transfer
Introduction
Style Transfer is the process in which one image is composed in the style of another image. We are going to use deep learning in order to make this possible. The process in itself is called neural style transfer and the technique comes from A Neural Algorithm of Artistic Style (by Gatys et al.).
Neural style transfer is an optimization technique that takes two images - a content image and style reference image. The deep net blends these images together so that the output image looks like the content image, but it seems as though it were “painted” in the style of the reference image.
The implementation involves optimization of the output image to match the content statistics of the content image and the style statistics of the reference image. These statistics are extracted from the images using a convolutional network.
Understanding the Model - VGG19
The first VGG model was made at the Visual Geometry Group (VGG) at the University of Oxford, hence the name of the model (Read more here ). It was inspired by AlexNet, the first Convolutional Neural Network (CNN) used in the ImageNet competition, and the one that got aware of the utility of CNNs for image processing.
The architecture of the model is as shown below:
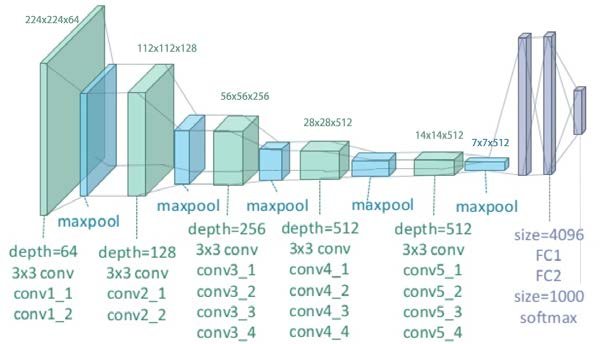
A fixed size RGB image is given as input. The only preprocessing that happens is that the mean RGB value, computed from the whole training set, is subtracted from each pixel. Spatial padding is used to preserve the spatial resolution of the image. A Rectified linear unit (ReLu) is used to introduce non-linearity to improve the model and improve computational time. (Over the previous versions of VGG, other functions like tanh and sigmoid were used, but ReLu proved to be much better than those.)
Although the initial purpose of the VGGnet was to win the ImageNet competition, it has been used in a lot of ways such as transfer learning and for style transfer.
Approach
One of the most significant outcomes of the Gatys paper was that representations of style and content in the CNNs are seperable. This means that we can manipulate bot representations independently to produce new images.
As CNNs are trained on object recognition, they get more specific about the actual content of the image compared to the individual pixel values. Higher layers capture the content and their arrangement in the input image, but don’t contain information about the exact pixel values of the reconstruction. So, the feature responses of the higher levels are referred to as the content representation.
To get the representation of the style of the image, a feature space that was originally used to capture the texture information is used. This feature space, in turn, is built on top of the feature responses in each layer of the network. It is made of the correlations between different filter responses over the spatial extent of the feature maps. By getting the feature correlations of many layers, we get a stationary representation of the input image which captures texture information, but not global positioning and arrangement. This is refered to style representation.
The final image is synthesized by finding an image that simultaneously matches the content representation of the photograph, and the style representation of the reference image. This means that the global arrangement of the picture is preserved, but the local colors and textures are provided by the reference style image.
However, both style and content can’t be completely disentangled from each other. The synthesis of the image includes a loss function that is minimized. This loss function contains two terms for the content and style respectively that are computed seperately. This way we can specify whether we want to provide more emphasis on the content or the style.
Implementation
The images are first preprocessed in order to be used by VGG19. TensorFlow.Keras contains the VGG19 model, which contains a preprocess_input() function for this purpose. We get the processed input.
As mentioned in approach, the content representation comes from the feature responses of the higher layers. The style representation comes from multiple feature responses from all layers. We define content_layers and style_layers so that they correspond to the layers needed.
The next step involves a function getting the model. As mentioned, TensorFlow.Keras has the VGG19 model. We load that, and train it using the ImageNet data. The model is then marked as non-trainable, so that the weights cannot be interfered with again.
After this, we define functions for computing losses. The total loss is defined as the sum of the content loss and the style loss. The content loss is easily found - it is just the root mean sqaured error in the target image compared to the content image. For computing the style loss however, we first need to process our data through a Gram Matrix. Applying a gram matrix to features extracted from a CNN removes the content information and helps create texture information. The loss is then computed as the mean square error between the gram output and the original style reference image.
This is the main implementation. We then have functions for gradient descent and for computing loss and gradients. Finally, everything is run in an optimization loop, and the most optimal image is found and displayed.
The model was then hosted to the internet in the form of a Flask app.
Results
Let the content image be:

Let the style image be:

Running the model for 1000 iterations, we get the following results.
Total time taken (on Google Colab): 134.7341s
| Number of iterations | Style Loss | Content Loss | Total Loss |
|---|---|---|---|
| 0 | 5.7769e+08 | 0.0000e+00 | 5.7769e+08 |
| 100 | 1.6871e+07 | 1.5939e+06 | 1.8465e+07 |
| 200 | 6.3584e+06 | 1.3791e+06 | 7.7375e+06 |
| 300 | 3.2306e+06 | 1.1993e+06 | 4.4299e+06 |
| 400 | 2.0485e+06 | 1.0201e+06 | 3.0686e+06 |
| 500 | 1.4694e+06 | 9.0234e+05 | 2.3717e+06 |
| 600 | 1.1519e+06 | 9.1799e+05 | 1.9699e+06 |
| 700 | 9.6703e+05 | 7.5486e+05 | 1.7219e+06 |
| 800 | 8.5002e+05 | 7.0624e+05 | 1.5563e+06 |
| 900 | 7.6842e+05 | 6.6915e+05 | 1.4374e+06 |

The final processed image is:

We can clearly see the style transfer that has taken place.
Conclusion
Using deep learning, I have successfully made a real time style transfer model that prints an image rendered in the style of another image’s creator. I used TensorFlow and the VGG19 model to achieve the task. The model was trained using the ImageNet repository and I tested the model and reported the results.