Mentors
- Pranav Koundinya
- Ashrith D R
Members
- K V Srinanda
- Dev Goti
- Shubham Swadi
- Sushree Shivani Sethi
- D Jagannadha Reddy
Aim
The project entails two main objectives: to understand the entire architecture of the underlying neural network, and to implement a deep learning based image processing algorithm on an embedded device, namely the Arduino Nano 33 BLE Sense.
Introduction
Recently CNNs(Convolutional Neural Networks) have played a key role in various image processing tasks. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. MIRNet Architecture has been designed in such a manner that it achieve both the goals collectively: Maintaining spatially precise high-resolution representations through the entire network and receiving strong contextual information from low resolution representations. We have adopted the MIRNet architecture for this project and have referred to a research paper for the same.
MIRNet Architecture
The core of the MIRNet Architecture is a multi-scale residual block containing several key elements:
(i) parallel multi-resolution convolution streams for extracting multi-scale features.
(ii) information exchange across the multi-resolution streams.
(iii) spatial and channel attention mechanisms for capturing contextual information.
(iv) attention based multi-scale feature aggregation.
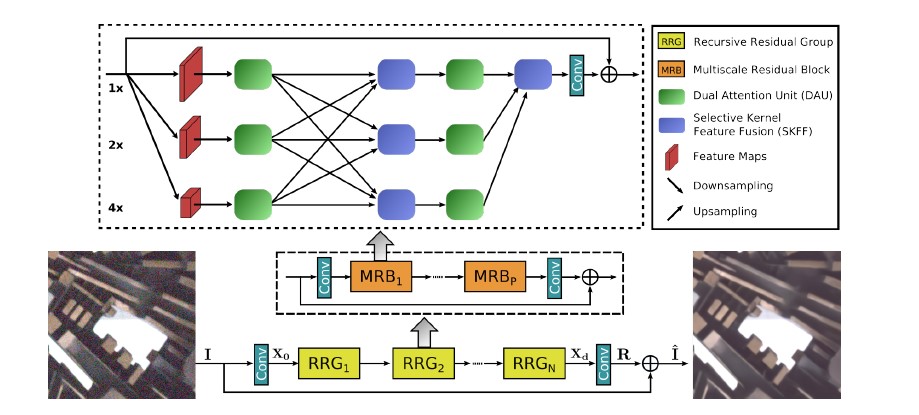
Overall Pipeline
Let 𝐈 be an Image of dimensions ℝHxWx3. The network first applies a convolutional layer to extract low-level features 𝐗𝐎 ∈ ℝHxWxC. Next, the feature maps 𝐗𝐎 to pass through N number of recursive residual groups (RRGs), which yield deep features 𝐗𝐝 ∈ ℝHxWxC. RRG contains several multi-scale residual blocks. In the next step we apply one more convolutional layer to deep features 𝐗𝐝 to obtain a residual image 𝐑 ∈ ℝHxWx3. The restored image is obtained as follows: Î = 𝐈 + 𝐑. We use Charbonnier loss to optimize our proposed network.
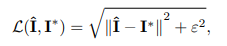 where,
where,
𝐈* denotes the ground-truth image
ε is a constant which we empirically set to 10-3 for all the experiments.
Multi-scale Residual Block (MRB)
Multi scale residual block is capable of generating a spatially-precise output by maintaining high-resolution representations, while receiving rich contextual information from low-resolution representations. The MRB consists of multiple (three in this instance) fully-convolutional streams connected in parallel. It allows information exchange across parallel streams in order to consolidate the high-resolution features with the help of low-resolution features, and vice versa. The components of MRB are described as follows:
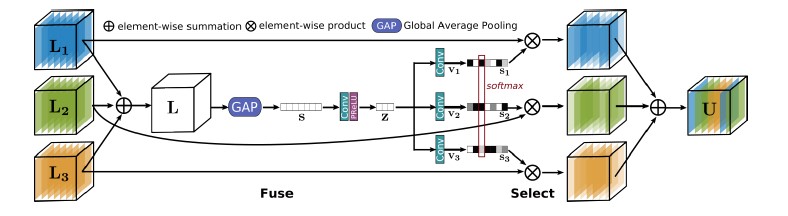
1. Selective Kernel Feature Fusion (SKFF)
SKFF module performs dynamic adjustment of receptive fields via two operations: Fuse and Select.The fuse operator generates global feature descriptors by combining the information from multi-resolution streams. The select operator uses these descriptors to recalibrate the feature maps (of different streams) followed by their aggregation.
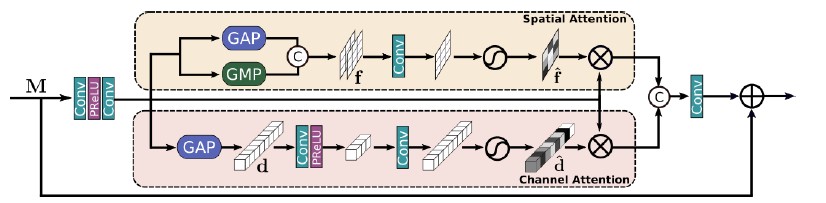
2. Dual Attention Unit (DAU)
While the SKFF block fuses information across multi-resolution branches, there is a need for a mechanism to share information within a feature tensor, both along the spatial and the channel dimensions. For this purpose we require DAU and the feature recalibration is achieved by using channel and spatial attention mechanisms.
Channel Attention branch exploits the inter-channel relationships of the convolutional feature maps by applying squeeze and excitation operations
Spatial Attention branch is designed to exploit the inter-spatial dependencies of convolutional features.
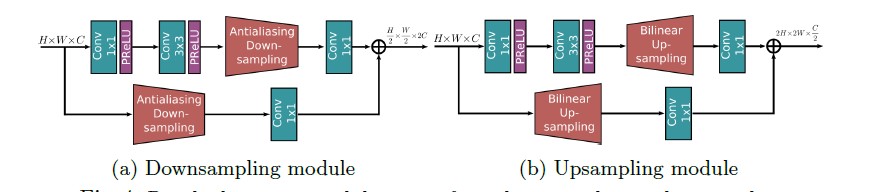
3. Residual Resizing Modules
In order to maintain the residual nature of the architecture(refers to the use of skip connections to create residual blocks that allow information to flow directly from one layer to another, bypassing one or more intermediate layers), we introduce residual resizing modules to perform downsampling and upsampling operations.
Dataset
For the purpose of image enhancement, the architecture is trained on LoL dataset. LoL is created for low-light image enhancement problems. It consists of 485 images for training and 15 images for testing. Each image pair in LoL consists of a low-light input image and its corresponding well-exposed reference image.
Performance & Results
We tried varying the number of MRBs(Multi-scale Residual Blocks) and RRGs(Recursive Residual Groups) in the MIRNet Architecture and tested their performances.The results are as follows:
Baseline Model: 3 RRGs & 2 MRBs
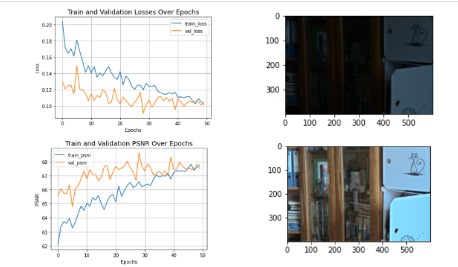
Model 2: 3 MRBs & 3 RRGs

Model 3: 1 MRB & 3 RRGs

Model 4: 1 MRB & 1 RRG

Model 5: 2 MRBs & 2 RRGs

Hardware Used
Arduino Tint Machine Learning Kit containing:
- Arduino Nano 33 BLE Sense Board with headers
- OV7675 Camera Module
- Tiny ML shield
- USB Cable
Jumper Cables, 9V Batteries (2 nos.), Breadboard.
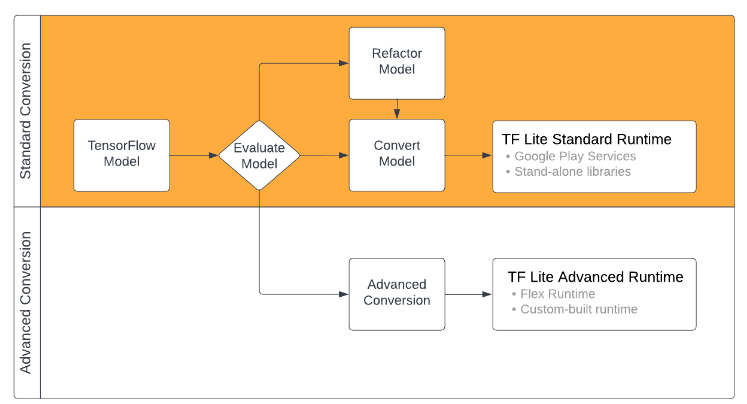
TensorFlow to TensorFlow Lite Conversion
Conclusion
We were able to train the model using MIRNet architecture and desirable results were obtained.
References
- Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang and Ling Shao, Learning Enriched Features for Real Image Restoration and Enhancement
- https://github.com/swz30/MIRNet
- https://github.com/soumik12345/MIRNet
- https://keras.io/examples/vision/mirnet/