Mentors
- Krishna Swaroop
- Shreeraksha Aithal
Members
- Anirudh Achal
- Sidharth Lanka
- Harsh Rathore
Human Parsing
Introduction
The goal of Human Parsing is to segment a 2-D image of a person into key human parts and poses.
In this section we briefly talk about the tasks and the models which are used in the project. Semantic Segmentation is the task of recognizing, and understanding what’s in the image at the pixel level. It is more difficult than most of the traditional methods. Given an image input it labels regions with different classes. For e.g. human, car, tree, sky, etc. Human Parsing is the task of segmenting a given human image into different semantic parts.
The aim is to assign each pixel from the human image to a semantic category like arms, legs, dress,etc. The models that we implemented are densenet, resnet 18, resnet 34, resnet 50, resnet 101 and resnet 152. We have used the PSPnet architecture which takes into account the global context of the image which can’t be captured by FCN based pixel classifiers.
Semantic Segmentation
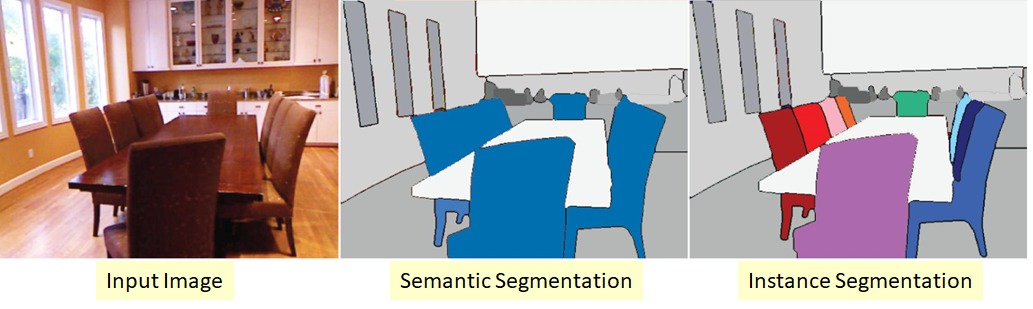
Semantic segmentation, or image segmentation, is a Computer Vision task where we label each pixel of an image with a corresponding class among a set of predefined classes as to what is being represented by that image. In Semantic Segmentation, multiple occurrences of a given object (say a car) are all given the same color code as they all belong to the same class, i.e., instances of an object aren’t differentiated and their respective pixels are assigned the same color. When pixels corresponding to distinct instances of the same class are given a different color, it is called Instance segmentation. Semantic Segmentation has its useful application in various fields like autonomous driving, medical image diagnostics, robotic vision, and many more.
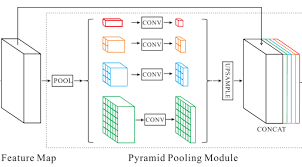
Most semantic segmentation networks work on high-resolution images which involve heavy processing at every scale, which proves to be quite computationally intensive. We have used Pyramid Scene Parsing Network (PSPNet) in our project, which can work on low-resolution images, and uses multiple scales of pooling to effectively extract features at different scales. As an addition to a standard feature extraction network (ResNet, DenseNet, etc), PSPNet applies 4 different max pooling operations with 4 different window sizes and strides. This effectively captures feature information from 4 different scales without the need for heavy individual processing of each one.
Dataset Structure
For this project, we used the LIP (Look into Person) dataset, a large scale dataset which focuses on semantic segmentation of a human being.
The single person dataset has been used for this project. The structure of the dataset is as follows :
LIP (folder) :
-
Testing Images
a. text_id.txt
b. Testing_images [10000 entries] - train_segmentations_reversed [30462 entries]
-
TrainVal_images
a. train_id.txt
b. train_images [30462 images]
c. val_id.txt
d. val_images [10000 images] - TrainVal_Parsing_Annotations
a. README_parsing,md
b. train_segmentations [30462 entries]
c. val_segmentations [10000 entries] - TrainVal_Pose_Annotations
a. lip_train_set.csv
b. lip_val_set.csv
c. README.md
d. vis_annotations.py
In the above dataset structure, the id.txt files contain the IDs of the images. For example, test_id.txt is a text file containing the names of all the testing images. The original training and validation images are present in the ‘TrainVal_images’ folder. The segmented images are present in the ‘TrainVal_Parsing_Annotations’ folder. The ‘train_segmentations_reversed’ folder contains the same segmented training images, but flipped along the vertical axis, i.e, data augmentation is performed, to achieve a higher accuracy and have more data.
Model Implementations
Pyramid Scene Parsing Network (PSPset) is the model that we chose to implement in order to accurately segment the various classes present in the dataset. It is basically a Pyramid Pooling Module used along with various different backbone implementations including Resnets and Densnets. In the Pyramid Pooling Module we use filters of 4 different scales (1, 2, 3, 6) and then combine the outputs after appropriate upsampling. This avoids loss in information and lets us capture all features from the coarsest ones to the finest ones. Below is a figure representing a Pyramid Pooling Module.
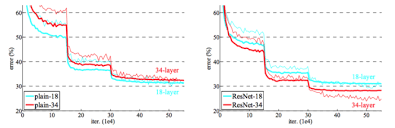
Residual Neural Networks (ResNets) are a neural network architecture that allows skip connection between various different layers in the neural network. As we increase the number of layers in vanilla neural networks, we observe the performance plateau or even reduce. One reason for this is that as the number of layers increases, it becomes increasingly difficult for the model to learn the identity function. Residual Neural Networks provide skip connections between various which allows the model to learn the identity function easily if required. This allows us to train very deep neural networks with over 100 layers without seeing a drop in performance. Below is a comparison of the performance of a plain neural network and that of a ResNet.
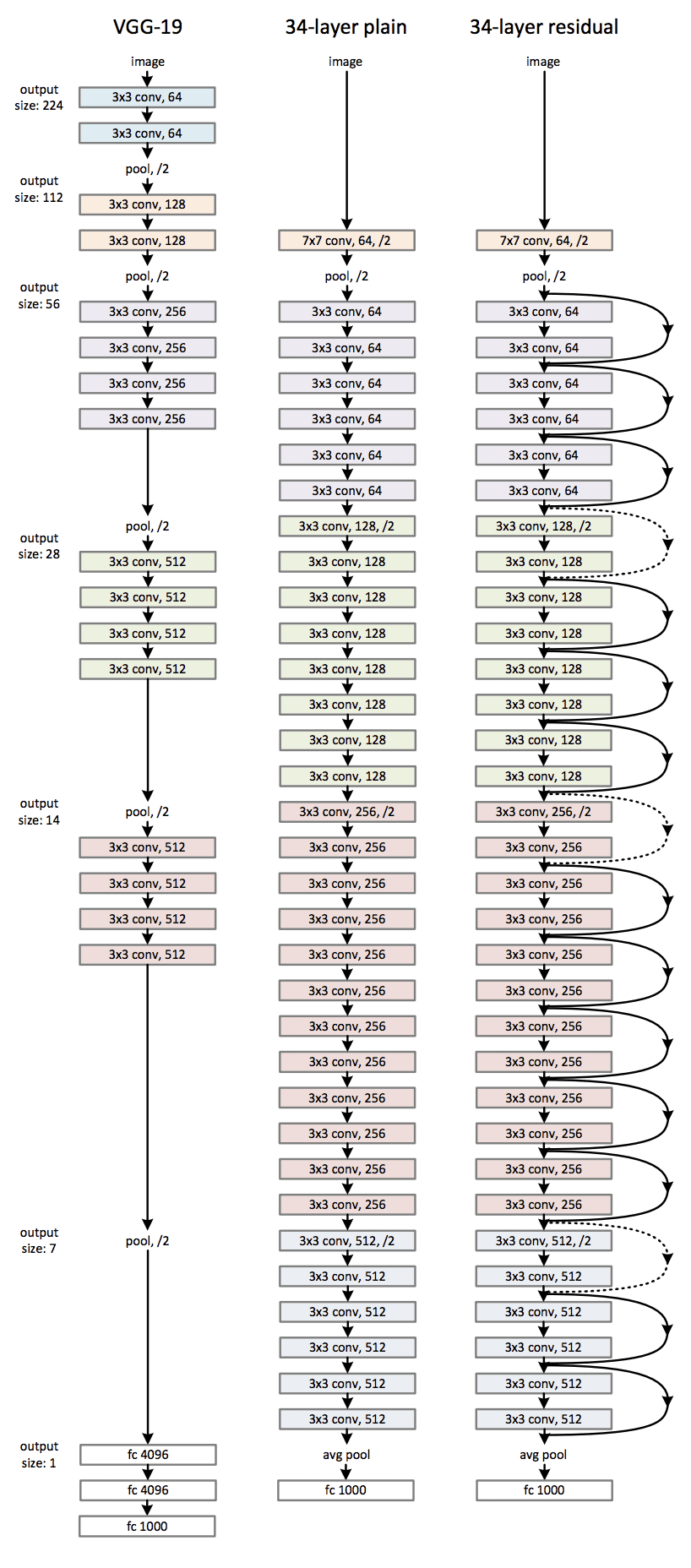
Below is a comparison of the model architecture for a plain 34 layer Neural Network with the model architecture for a 34 layer ResNet. We see the various skip connections present.
In our project, we have tried out the performance of the PSPnet using Resnet-18, Resnet-34, Resnet-50, Resnet-101 and Resnet-152 as a backbone.
Results
We achieve competitive results on the single human parsing LIP dataset.
| Model Name | Epochs | Overall Accuracy | Mean Accuracy | Mean IOU |
|---|---|---|---|---|
| Resnet 50 | 40 | 0.4782 | 0.1433 | 0.0719 |
| Resnet 34 | 30 | 0.4806 | 0.1589 | 0.0790 |
| Resnet 18 | 80 | 0.4916 | 0.1577 | 0.0800 |
| Resnet 152 | 10 | 0.4957 | 0.1393 | 0.0727 |
| Resnet101 | 30 | 0.5008 | 0.1472 | 0.0759 |
| Densenet | 80 | 0.4985 | 0.1515 | 0.0788 |
| Squeezenet | 80 | 0.5127 | 0.1294 | 0.0712 |
We achieve the highest possible accuracy with Squeezenet with 51.2% overall. This was trained for 80 epochs. The results for various models are for varying epochs due to resource constraints, but the results are representative of various architectures used in the task.
Conclusion
In this project, we have developed tools and systems which can successfully segment a given 2d human image into its parts. To achieve this, we have leveraged the PSPNet framework and implemented various backbones to deepen the understanding of how modern day computer vision models work. We have trained and tested the implemented models qualitatively and reported the results.