Mentors: Achintya K N, Akash S Bharadwaj, Sankarsh R
Group Members: Amogh Umesh, Anirudh Singh Solanki, Bhakti Jayannache, P M Prasanna
Objective
For face recognition, there are two types of comparisons: Verification and Identification.
- Here we look to address the identification problem.
- Build an attendance system for an organization that uses the uniqueness of an employee’s face.
- Train a CNN model to extract features from an image and compare it with a database to identify the face.
Attendance System
The live image is fed to the detection algorithm. The face is cropped and processed to match our model input requirements. The database has the facial features of all working employees. The attendance is marked based on a comparison of features of the cropped face and the features in the database of employees using a certain threshold.

Face Detection Using Haar Cascades
Face detection is the process of detecting the presence of a face and finding its position in the image. Here, we used Haar Cascades to detect faces. It is an approach where a cascade function is trained from a lot of positive and negative images to identify the location of the faces. Once the position of faces are obtained, the faces are cropped and fed into our feature extraction model to extract features and identify them.

Dataset
The dataset we used for our project is the Olivetti dataset. The dataset has 10 different images of 40 distinct people, which make a total of 400 images. All the images were taken at different times with varying lighting and expressions. All images are in grayscale. Each image is of the size 64 x 64. Each pixel is scaled to a real number in the interval [0,1].

Data preprocessing and triplets formation
Five random images were selected out of the ten available for each of the 40 people, which makes a total of 200 images. We then created three arrays: Positive, Anchor, and Negative. The images with the same index in the 3 arrays form a triplet. In this triplet, the positive and the anchor image belong to the same person. The negative image can be of any of the 39 people remaining. With the 200 images, we were able to create 1,56,000 triplet sets.

Feature extraction model (CNN Model)
This model takes an image as input and outputs 128 features of it. A CNN model was built for feature extraction that incorporated 4 convolutional layers and the last layer was a dense layer with 128 neurons (no. of features of face). The last dense layer had activation function “Sigmoid”, so that result is between 0 and 1.
Siamese network
This network takes three images namely anchor, positive and negative which trains to minimize the feature distance between anchor and positive image and maximize the feature distance between anchor and negative image using triplet loss function. The features are obtained using previously built feature extraction CNN model.
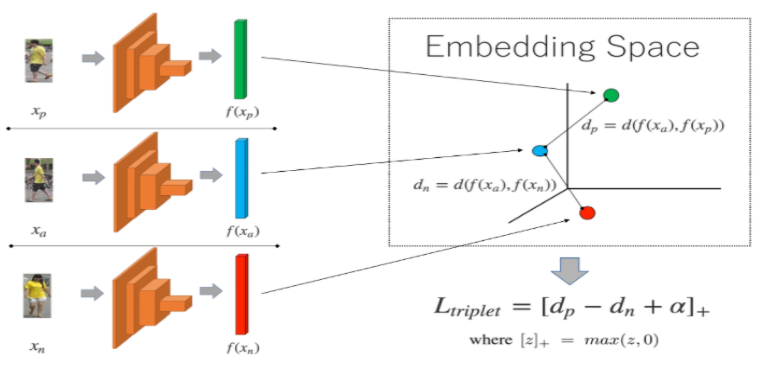
Triplet Loss
It is a distance based loss function that operates on three inputs:
- anchor (a) is any arbitrary data point
- positive (p) which is the same class as the anchor
- negative (n) which is a different class from the anchor
Mathematically, it is defined as: L = max(d(a,p) − d(a,n) + margin, 0)
Hyperparameters of training
- Train: Validation: Test = 0.9: 0.05: 0.05
- Learning rate =0.0001 (Adam)
- Batch size = 32
- Epochs = 30
- Feature distance comparison threshold = 20
Results
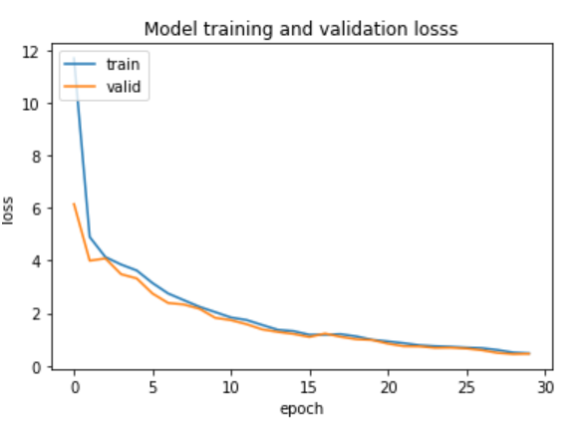
The features of anchor_test, pos_test and negative_test were extracted from feature extraction CNN model and distance of features between anchor_test, pos_test and negative_test were found. If distance between anchor and positive is less than threshold(20) it is treated as accurate. Similarly, if distance between anchor and negative is greater than threshold(20) it is treated as accurate. Accuracy on test set achieved: 99%
References
- Image Processing
- Deep learning and CNN
- Face detection
- Face recognition and subsequent videos
- Keras and OpenCV official documentation
You can find the related codes in our Github repository here.