Mentors
- K V Srinanda
- Mohammad Aadil Shabier
Members
- Aryan Herur
- Chanakya Pavan Kumar S
- Jyotsana Munnur Achal
- Prajna B. Shettigar
Acknowledgements
The datasets were prepared by EyePACS and hosted on Kaggle. We would like to thank the IEEE NITK Student Branch for conducting Envision 2023.
Aim
We aim to develop a CNN model that can classify the images of eye fundus into various categories based on the severity of diabetic retinopathy. Five DR stages, which are 0 (No DR), 1 (Mild DR), 2 (Moderate), 3 (Severe) and 4 (Proliferative DR) will be processed in the proposed work. The data is available in a Kaggle dataset which has been mentioned in the references. We aim to achieve a good level of accuracy while classifying the data thus solving the problem.
Introduction
People with diabetes are prone to an eye disease called Diabetic Retinopathy. Diabetic retinopathy is considered a deadly eye condition as it can cause a loss of vision and blindness in people who have diabetes. Diabetic retinopathy doesn’t show up with symptoms at first but eventually can worsen things up by causing vision loss. Diagnosing at an early stage can help oneself save their vision. This is the problem we wish to solve with this project.
Libraries and Frameworks
The CNN model was developed using Keras framework of TensorFlow. We use other Python libraries such as Pillow, Numpy, Pandas, Matplotlib for image processing, data manipulation, analyzing data, plotting graphs, etc.
Dataset
The original dataset consists of large set of high-resolution retina images taken under a variety of imaging conditions. A clinician has rated the presence of diabetic retinopathy in each image on a scale of 0 to 4, according to the following scale:
- 0 - No DR
- 1 - Mild
- 2 - Moderate
- 3 - Severe
- 4 - Proliferative DR
The images in the dataset come from different models and types of cameras. Due to the huge size of the dataset, we replaced the dataset with a reduced dataset found on Kaggle. The reduced dataset contains all the images as the original dataset scaled down to a dimension of (224, 224).
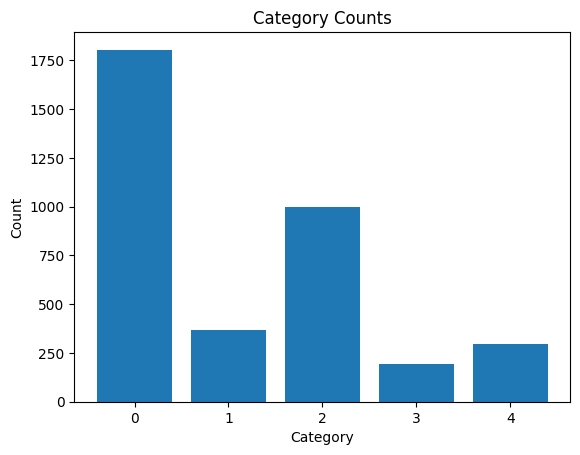
The dataset was seperated into two parts: a test dataset containing 80% of the images, and a validation dataset, containing 20% of the images.
Preprocessing
The images were combined into an (image, label) pair for the purposes of training. The image consists of 3 channels: red, green, blue. Each value consisted of an integer from 0-255.
Rescaling
The images were converted from the 0-255 range to 0-1 range by dividing them by 255. This makes it easier to work with as neural networks perform better with things in the similar scale.
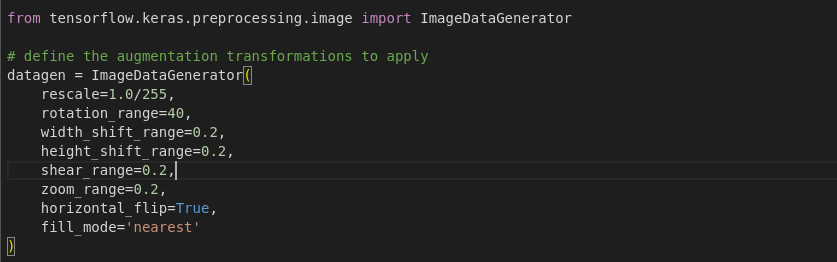
Data Augumentation
Data augumentation is a techinque used to artificially increase the size of the dataset by creating modified copies of the dataset using existing data. The image is modified by adding a random rotation, random shear, random translations, random noise. This makes the model more robust as it has to learn to deal with irregularities in data.
Model Architecture
Various different models architectures were tried out, each achieving different accuracies. The input layer has the shape (224, 224, 3) and the output layer has a shape of (5,) one for each class. The loss function used was the categorical cross entropy function and the optimizer was the Adam optimizer with default parameters.
Simple Model
The first model we used was a simple CNN which contains a convulational layer followed by a max pooling layer. This patter was repeated 6 times. This was followed by 2 dense layers.
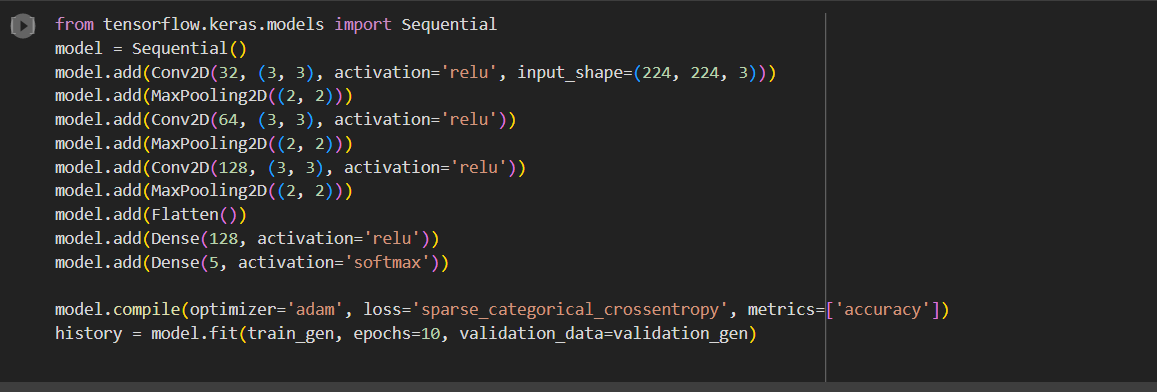
The model achieved best accuracy of 71.8% on the training data and 73.12 on the validation dataset.
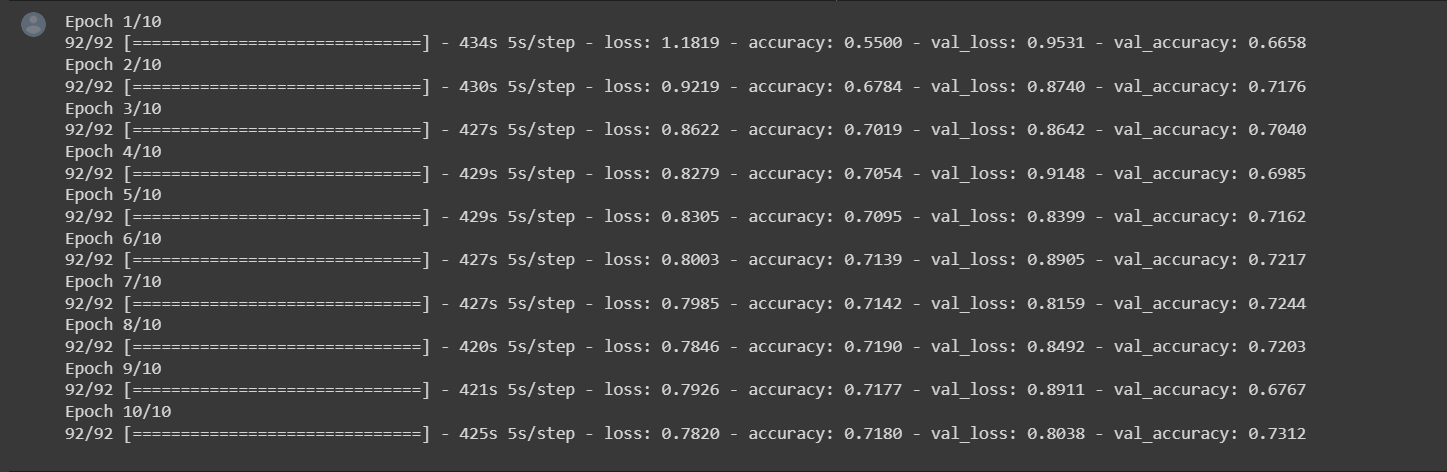
The better accuracy in the validation dataset can be explained by the fact that when we use data augmentation, the model sees a larger and more diverse set of images during training, which helps it to generalize better to new, unseen data. This may have resulted in better validation accuracy.
Introducing dropout
The next version of the model used dropout regularization to better train the model.
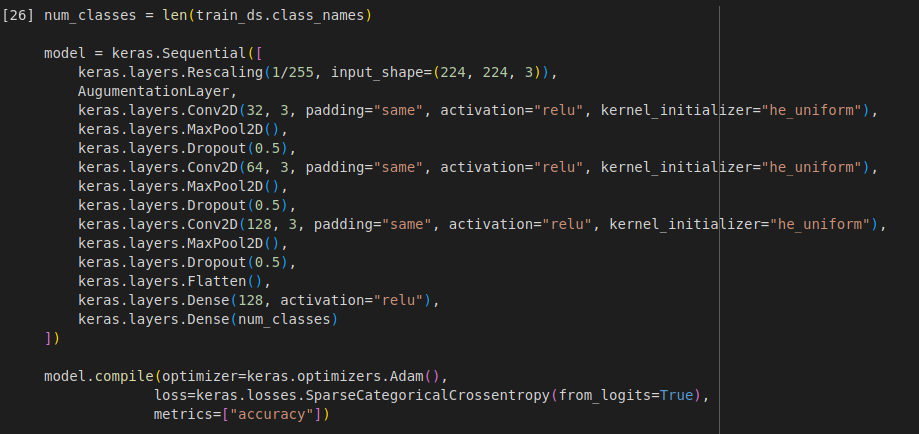
The model acheived a training accuracy of 71.8% and validation accuracy of 73.12%
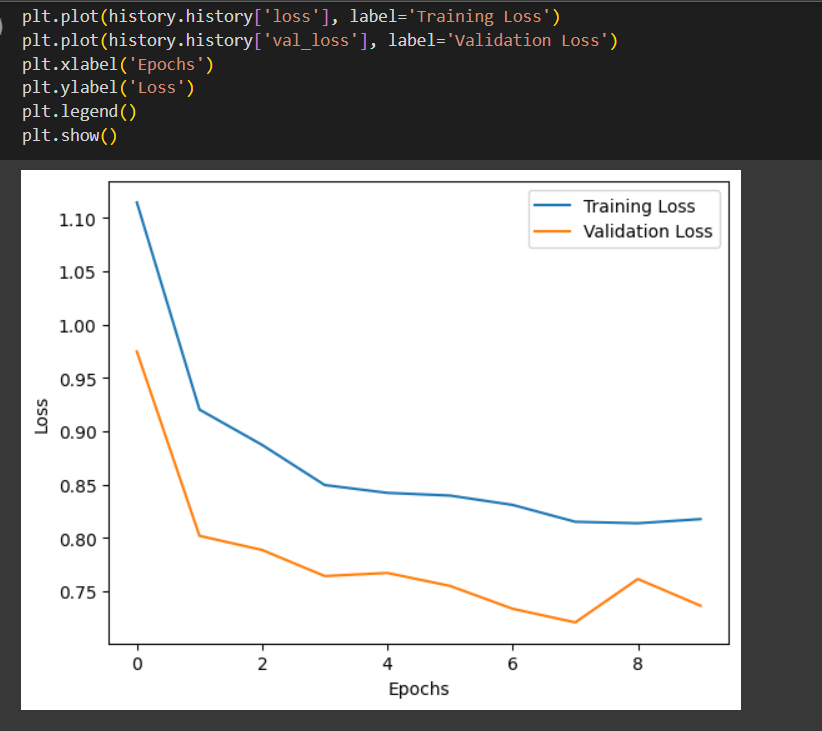
Transfer Learning Model using VGG-16
Transfer Learning is a popular technique in the field of Deep Learning that allows us to use pre-trained models and apply them to different tasks. This technique works by using a pre-trained model as a starting point and then fine-tuning it on a new dataset for a new task. Transfer Learning saves time and computational resources by reusing the knowledge learned from previous tasks and applies it to new ones.
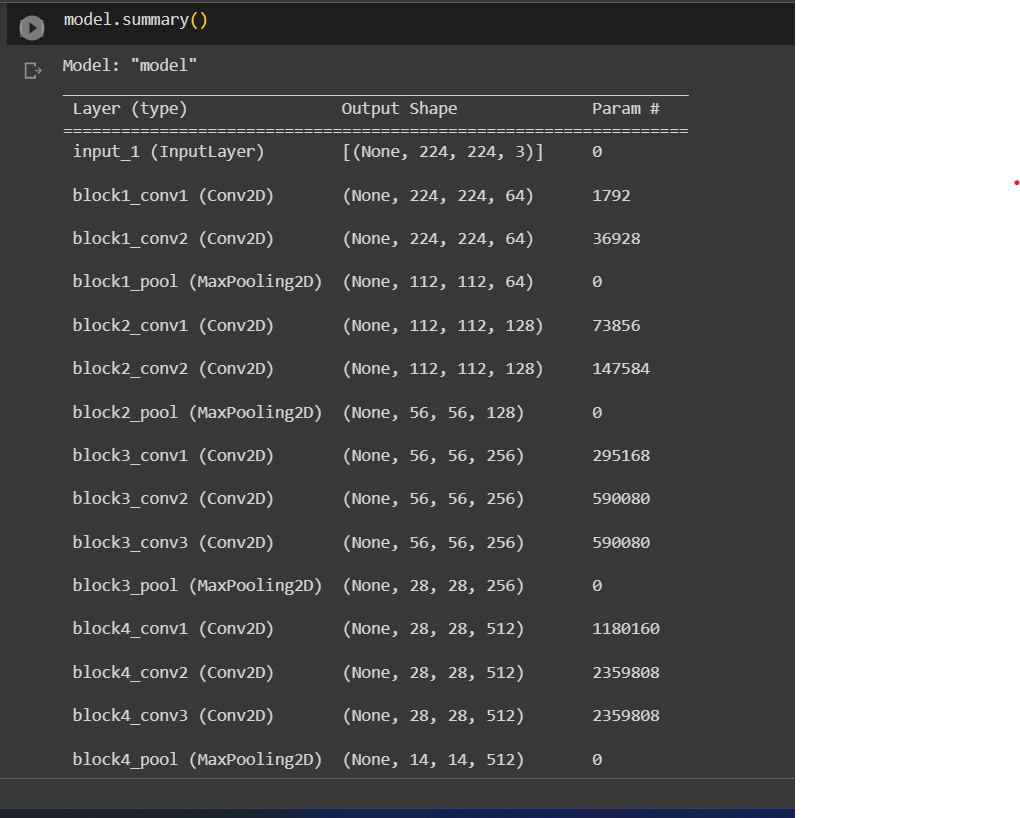
VGG 16 is a convolutional neural network architecture that was introduced by researchers at the University of Oxford in 2014. VGG 16 consists of 16 layers, including 13 convolutional layers and three fully connected layers. The model is known for its simplicity and its ability to achieve high accuracy on image classification tasks.
VGG 16 has been pre-trained on the ImageNet dataset, which consists of over 1 million images with 1000 classes. As a result, it has learned to extract high-level features from images that are useful for a wide range of computer vision tasks, such as object detection, image segmentation, and image classification.
Transfer Learning with VGG 16 involves taking the pre-trained model and using it as a feature extractor. The pre-trained layers are frozen, and only the last few layers are retrained on a new dataset for a new task. This approach helps to achieve better accuracy with less training data and fewer computational resources.
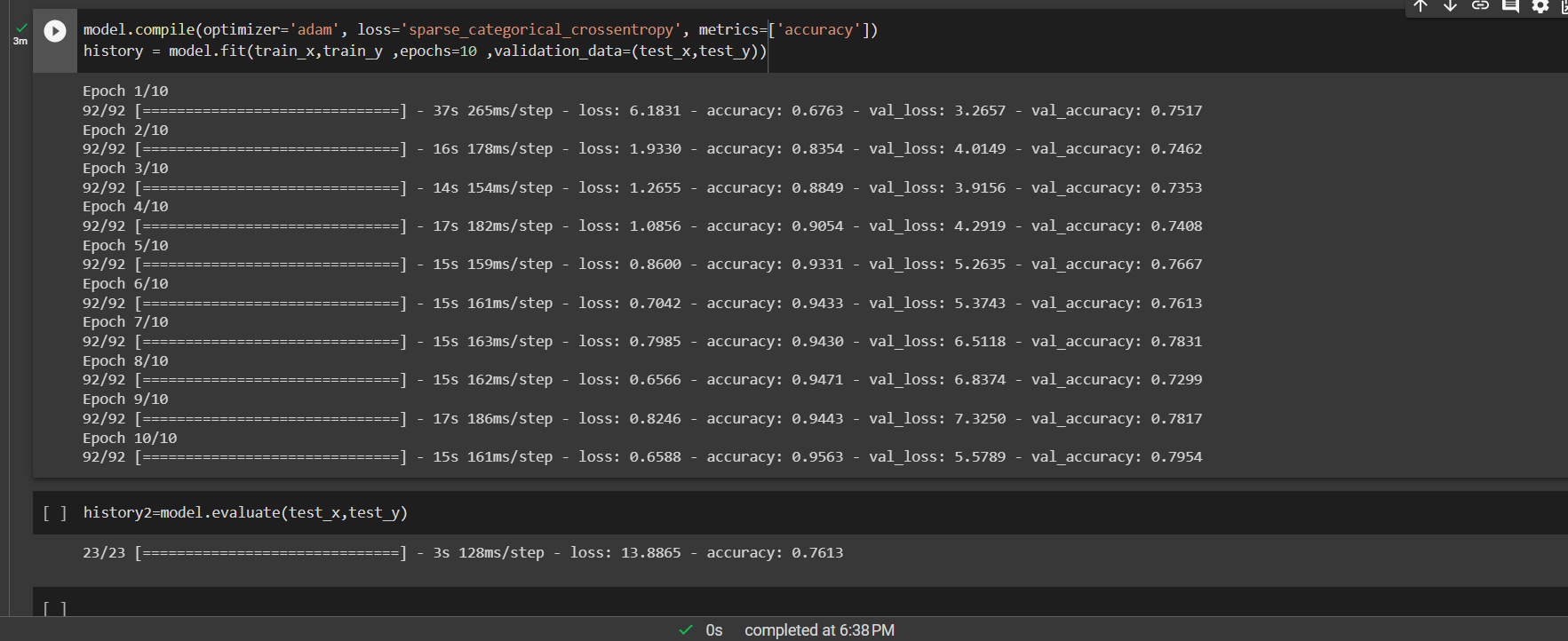
Without data augumentation, the model reached a maximum training accuracy of 95.63% and validation accuracy of 79.54%. We spectate that the data augumentation might have worsened accuracy because of the nature of this dataset.
Conclusion
In conclusion, we have presented a successful approach for the classification of diabetic retinopathy using convolutional neural networks (CNNs). Our proposed model achieved good accuracy and specificity in identifying different stages of diabetic retinopathy from the eye fundus images. Future work should focus on addressing the limitations of our study and exploring other methodologies to further improve the performance of the model.