Faculty Guide
- Dr. Aparna
Mentors
- Bhaskar Vyas
- Rahul M Hanchate
Members
- Achintya K N
- Vineeth Narayana
Stereovision and Time of Flight Methods
Definitions of some terms frequently used in the blog:
Disparity: Disparity refers to the apparent pixel difference or motion between a pair of stereo images. To experience this, try closing one of your eyes and then rapidly close it while opening the other. Objects that are close to you will appear to jump a significant distance while objects further away will move very little. This difference between the pixel locations of the same objects in the two images is called as disparity.
Depth map: An image channel which quantizes the depth information of each pixel. Cost computation: Computational cost is the execution time per time step during simulation. Improving this will inturn improve the efficiency of the procedure and inturn the accuracy of the output.
FIFOs: FIFOs in computing are a way of storing data in a First-In First-Out basis, i.e., the data at the head of the storage element will be processed first.
Line buffers: Line buffers are a way of dealing with images in hardware implementations as entire images cannot be processed at once and thus each row of an image are sent in 1D array streams one after the other until all the rows are accounted for. Convolutional Neural Networks: A convolutional neural network (CNN) is a type of artificial neural network used in image recognition and processing that is specifically designed to process pixel data. A neural network is a system of hardware and/or software patterned after the operation of neurons in the human brain.
Stereovision
Stereovision is the extraction of 3D information from 2D images. By comparing the information of a scene from 2 different vantage points, 3D information can be extracted about the particular scene by examining relative positions of objects. This concept is very similar to how vision works in animals, the information taken in by the 2 eyes allows animals to make accurate estimates of the depth of their surroundings.
In traditional stereo vision, two cameras, displaced horizontally from one another are used to obtain two differing views on a scene, in a manner similar to human binocular vision. By comparing these two images, the relative depth information can be obtained in the form of a disparity map, which encodes the difference in horizontal coordinates of corresponding image points. The values in this disparity map are inversely proportional to the scene depth at the corresponding pixel location.
However, Stereo Correspondence is one of the most active areas of research in Computer Vision and there are various algorithms that have been proposed over the years to obtain accurate results.
Stereo algorithms generally perform the following 4 steps,
- Matching cost computation
- Cost Aggregation
- Disparity computation
- Disparity refinement
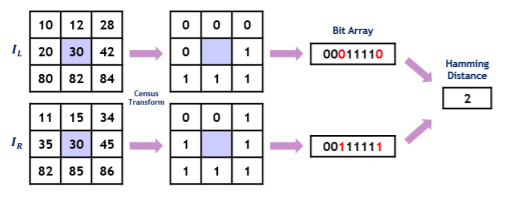
For Matching, the algorithm we are going with is called the Census Transform. It is a non-parametric local transform of a 2D array which depends on the comparative intensity of a Pixel P versus the pixels in its immediate neighborhood N(P).
The Census transform uses the relative intensity of input images; it is robust to intensity variations of input images. Let C(P) be the census transform of a pixel P. C(P) maps the local neighborhood of surrounding a pixel P to a bit string representing the set of neighboring pixels whose intensity is less than that of P. The census transform converts the relative intensity differences to 0 or 1 into the one-dimensional bit array form.
Two pixels of the census transformed images are compared for similarity using the Hamming distance, which is the number of bits that differ in the two bit strings as shown (this is done by performing an XOR operation between the bit strings). To compute the correspondences, the Hamming distance is minimized after applying the census transform.
Some other algorithms in the reckoning were the Rank tranform for Stereo Matching. This algorithm essentially transforms each pixel into their respective ranks. Rank is an integer which represents how large an element is compared to the other elements belonging to its row and column. Also traditional stereo-matching algorithms use the Sum of Squared Differences algorithm to compute the disparity values of pixels. It essentially computes the differences between the pixel values at corresponding locations in the two images (left and right).
Progress on this so far
The necessary research for the same was carried out and after much deliberation, the census transform algorithm was chosen as the algorithm for stereo-matching since it produced decent results with better accuracy compared to the rest and also showed a lot of promise for the hardware implementation.
Census transform coded in python provided us with a better pixel values to find depth, the result is shown below


Finally, to find the depth the hamming distance is found, giving us the resultant depth image as

Some of these codes could be found at:
https://github.com/IEEE-NITK/Depth_estimation_on_FPGA/tree/final-codes
Also, the verilog code for the same is almost complete which defines a hardware architecture for the algorithm as shown below.
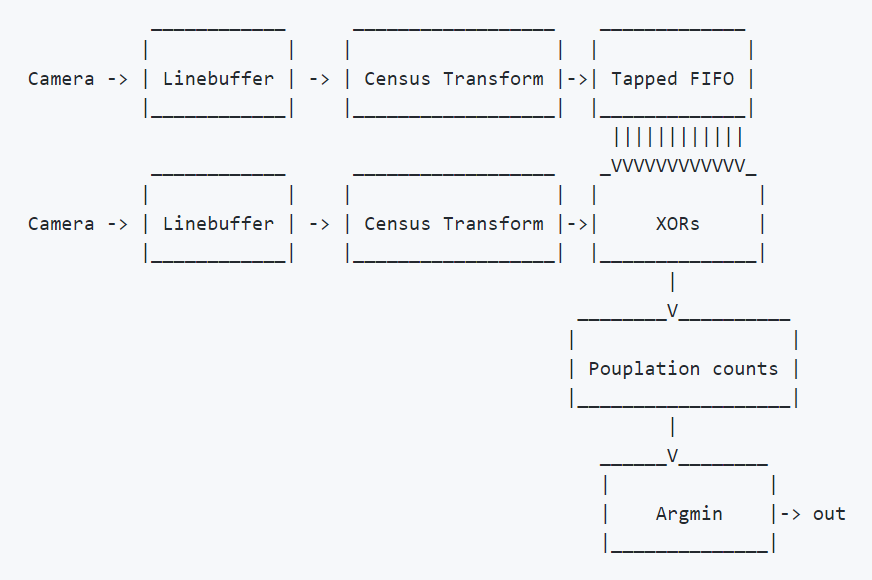
Since, Verilog cannot read images we use a line buffer to take a lines of pixels from the images and then perform census transform on it. Then the left pixels are iterated through the right to get hamming distances.
For iteration we use a tapped FIFO and then for getting hamming distance we can use an Xor gate and the difference in binary numbers give 1 through xor gates.
Then the argmin or the minimum of the hamming distance is taken as the disparity.
Time of Flight method
Special ToF cameras are used for the depth estimation using this method. A ToF camera uses infrared light (lasers invisible to human eyes) to determine depth information - a bit like how a bat senses it surroundings. The sensor emits a light signal, which hits the subject and returns to the sensor. The time it takes to bounce back is then measured and provides depth-mapping capabilities.
Since any electro-magnetic radiation travels in the air at the constant light speed, the distance covered by an optical radiation in a certain time is simply the product between light speed and time. The required Hardware consists of just a radiation emitter (TX) and a receiver (RX), ideally both co-positioned.
LIDAR (Light and Radar) sensing technology can be used for the hardware but it requires point-by-point ToF measurements which makes it ill-suited for depth estimation of dynamic scenes.
Hence, we can use Matricial ToF Cameras which are essentially an extension of the LIDAR sensors, where the whole scene is captured using a set up of NxM sensors at once allowing dynamic depth estimation (even for video data) for real-time applications. These can also be integrated in a single CMOS chip making the whole setup compact and easy to handle. However, some tradeoff in resolution and quality will have to be accepted.
Combining the two methods of Depth Estimation to obtain a high accuracy depth map for a scene
So two different disparity maps have been computed,one from a ToF camera and one from a stereo system. Due to their complementary characteristics, it is reasonable to combine them in order to obtain a better disparity map. If someone would be able to label each pixel according to the disparity correctness, it would be sufficient to select, for each pixel, the correct hypothesis among the two provided. Therefore the best way to discriminate among different hypothesis is to associate some kind of confidence information.
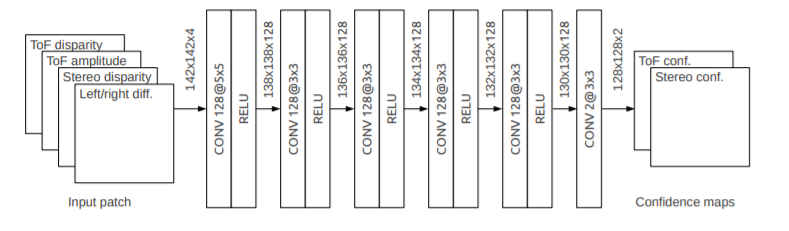
For obtaining confidence maps, a Convolutional Neural Network was used. It contains a stack of six convolutional layers each followed by a ReLU non-linearity with the exception of the last one. The firs five convolutional layers have 128 filters each, the first layer has a window size of 5 × 5 pixels while all others have a window size of 3 × 3 pixels. The last convolutional layer has only two filters, producing as output a two-channels image where the two channels contain the estimated ToF and stereo confidence respectively. In order to produce an output with the same resolution of the input, no pooling layers have been used. At the same time, to cope with the boundary effect and size reduction introduced by the convolutions, each input image is padded, where the padded values are set to be equal to the values at the image boundary. Middlebury dataset was used for training puprose.
We also intended to develop hardware accelator for CNN using verilog which will have blocks as shown below (currently in development).
Now, to obtain fusion of the disparity maps from the upsampled ToF camera and the stereo vision system using the confidence information estimated by the deep learning framework, we used Locally Consistent (LC) technique. The idea behind the method is to start by computing the plausibility of each valid depth measure at each point. The plausibility is a function of the color and spatial consistency of the data. Multiple plausibilities are then propagated to neighboring points. In the final step the overall plausibility is accumulated for each point and a winner-takesall strategy is used to compute the optimal disparity value. Result of approach is shown as below.

Future Works
All effort will be made to implement the combining methodology discussed previously and also to come up with decent hardware architecture for the same so as to implement it on an FPGA.