Mentors:
- Garvin Pokhra
- Nakshatra Gopi
Members:
- Pranav Koundinya
- Samiran Vanmali
- Raghuram Kannan
Abstract:
Apps like Shazam can recognize a song from a large cluster of audio. This can't be done just by using brute force to compare an audio sample to every song in the database. In this project, we have attempted to save the effort by the hashing method to explore audio fingerprinting. An audio fingerprint is a condensed digital summary generated from an audio signal that can be used to identify an audio sample or locate similar items in an audio database. Here, the audio file is fingerprinted, a process in which reproducible hash tokens are extracted. A hash is a unique, encoded string of a pair of distinguishable peaks in an audio signal. Both database and sample audio files are subjected to the same analysis. The fingerprints from the unknown sample are matched against a large set of fingerprints stored in the database. This is supplemented by MySQL serving as a database management system to store the hashes. The fingerprints of the recording are compared with those in the database to return the best match. We have also worked on a search algorithm to identify the audio fingerprint of the given audio sample from a database of songs.
Model:
Our proposed model tries to achieve the result in two phases:
- Learning the original songs and storing the fingerprints in the form of a large database (Training Phase)
- Record the audio track from the user and compare it with the database to return the best match (Testing Phase)
Implementation:
The treatment for audio signals in both phases remains the same. The first and foremost part of audio recognition is reading an audio signal and storing it in a form that can be processed upon. The recording is done by the microphone and saved as an audio file. The audio file is then loaded onto and stored as a two-dimensional array of amplitude against time.
Moving to the Fourier domain
The next process is to change the audio signal from the time domain to the frequency domain i.e., obtaining the frequency domain representation. This is achieved by the Fourier Transform of the audio signal, particularly the Fast Fourier Transform (FFT). Shown below is the plot of an audio signal in the time domain, along with its frequency-domain counterpart.

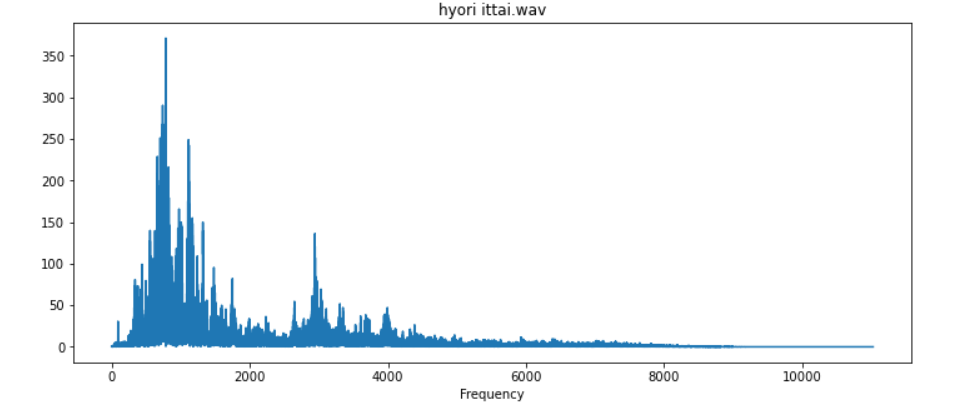
Visualizing frequency, amplitude, and time in a single plot
After obtaining the Fourier Transform, we need to generate a Spectrogram- a visual plot of the amplitude of the signal as a function of time and frequency. Before this, however, it is necessary to obtain the Short-Term Fourier Transform (STFT) of the audio signal by breaking down the audio signal into numerous small chunks and performing the Fourier Transform on each of them. A spectrogram of an audio file looks something like this.
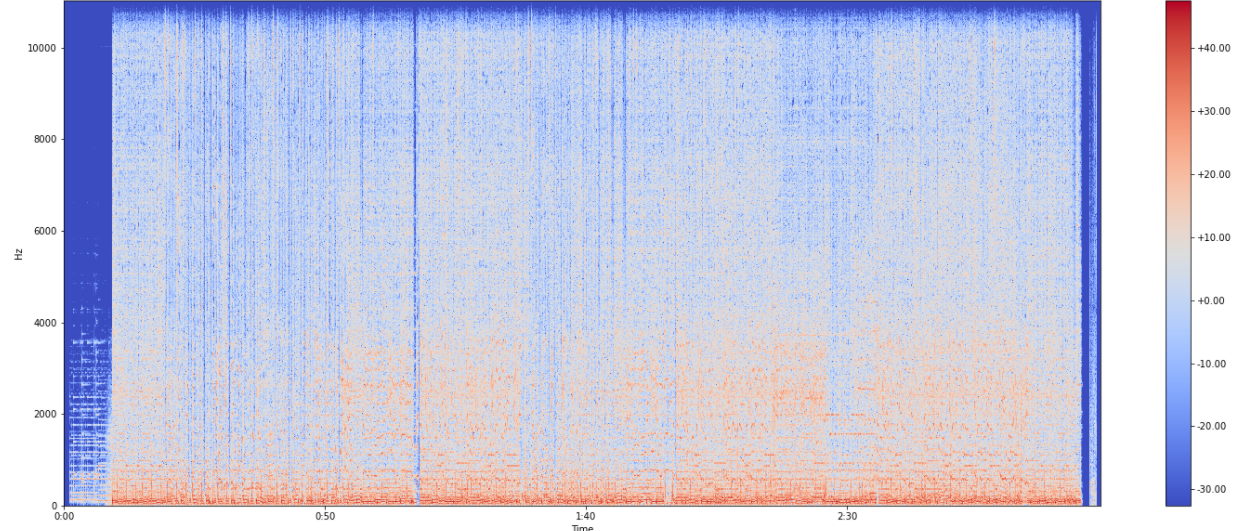
Mapping the peaks
Although the plot gives information about the audio file, it has little meaning or significance to the computer. In principle, the processing is done on the two-dimensional array which stores the STFT coefficients of the audio file. This array contains numerous points/elements of local maxima, called the peaks. The peaks are mapped by masking; parsing a kernel of a predefined dimension over the entire array, and setting the points of local maxima to TRUE(1) and all other points to FALSE(0). An example of masking of a 5x10 matrix by a 3x3 kernel is shown.
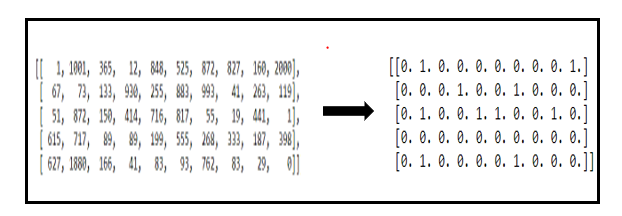
For each peak, a set of neighboring peaks are paired with and passed to a hash function to generate a hash. A hash function takes one or more inputs and generates an encoded string called a hash, which is unique for each input i.e., any change in input is reflected in the hash, and the same inputs give the same hashes. The hash value, along with the time component of the peak (referred to as the offset), is called the audio fingerprint. The same process is performed in the case of a recording as well.
After feeding an audio track to the system, performing FFT in overlapping windows over the length of the song, extracting peaks, and forming fingerprints; we have to store them in the MySQL database. Assuming we've already performed this fingerprinting on known tracks, i.e. we have already inserted our fingerprints into the database labeled with song IDs, we can now simply match the audio file.
Recognition
Prior to the process of recognizing the song, an empty dictionary is created for each song in the database.
Each hash value obtained for the recording is compared with that in the database. When a hash value matches with that in the database, the dictionary of the corresponding song gets appended with a key-value pair, where the difference between the database offset and sample offset is the key, and the number of repeating matches in the song for the same hash is the value. This process is carried out for each hash in the recording. The maximum "value" in each dictionary is taken as the score for the respective song. The song which has the maximum score is the best match for the recording, and it is the recognized song.
Conclusion:
So, in conclusion, we can say that this project is useful for recognizing an audio file using the hashing method. In this project, we have used python and its various libraries, MySQL database, and written the code in Jupyter Notebook. We have successfully been able to recognize the sound by using spectrograms and finding the fingerprints; however, this project has its obstacles like making sure the sound is present in the database, the fingerprints of the sound are accurate even for a small portion of the sound. The future aspects for this project would be to use better noise filter techniques, adding more sounds to the database, finding optimized ways to get more accurate fingerprints, etc.
Resources:
- https://willdrevo.com/fingerprinting-and-audio-recognition-with-python/
- https://ourcodeworld.com/articles/read/973/creating-your-own-shazam-identify-songs-with-python-through-audio-fingerprinting-in-ubuntu-18-04
- https://towardsdatascience.com/understanding-audio-data-fourier-transform-fft-spectrogram-and-speech-recognition-a4072d228520