Mentors
- Nishant Nayak
- Sravani Katasani
- Mudit Singhal
Members
- Ashish Bharath
- Mohammed Ayman
Aim
To generate English Pseudocode from Python Code using Neural Machine Translation, made possible using Deep Neural Networks.
Introduction
For large codebases, code explainability is a major challenge. When dealing with unfamiliar codebases, it is common to spend more time learning the code than actually working with it. If a novice Python programmer attempts to read it, they may find it challenging to comprehend its behaviour. The behaviour of the source code may be better understood if the pseudo-code and flowcharts of the code were used at the same time.
With the use of Natural Language Processing, one can produce pseudocodes and flowcharts for any given Python code which can then help this process of comprehending code easier for developers. We propose to implement this application to generate pseudocodes and flowcharts as a web application so that developers can generate the pseudocode/flowcharts on any system that they work on.
What is Machine Translation?
Since the 1950s, training computers to translate two natural languages have been tedious. With the advent of machine learning and artificial intelligence in the early 2000s, this task became feasible with acceptable accuracy. Machine translation is a sub-field of computational linguistics that studies the use of software to translate text or speech from one language to another. In the modern-day, machine translation is used for various translation tasks, including Google Translate, translation of the text on social media platforms, translating event proceedings in the European Commission, etc.
Machine translation evolved significantly from its inception in 1951, from simple rule-based heuristics to statistical methods and finally using advanced Machine Learning techniques like Deep Neural Networks. The goal of machine translation has always been to effectively translate a sentence from a source language to a sentence in a target language while maintaining linguistic, semantic and syntactic similarities through the translation.
Machine Translation can broadly be classified into 3 types:
- Rule-Based Machine Translation, where handwritten rules are explicitly programmed to translate phrases from one language to another
- Statistical Machine Translation, and
- Neural Machine Translation
The latter 2 methods are explained below.
Statistical Machine Translation
SMT is a machine translation method where the translations are made based on previously seen bilingual corpora. The model makes a prediction on what the next word will be based on previously seen sequences of words. The statistical approach contrasts with the rule-based approaches to machine translation as well as with example-based machine translation. The idea for statistical machine translation comes from information theory where a probabilistic distribution p(T|S) that a string T in a target language is a translation of string S in the source language is modeled by applying various statistical and probabilistic techniques on a huge amount of textual corpora. Bayes theorem is one such modelling approach. Even though an SMT model would perform better than a Rule based model, it has its own downsides and is nowhere near to match accuracies with Natural Human Translation. An SMT model also performs poorly on a language pair with differing word orders and linguistic structure.
Neural Machine Translation
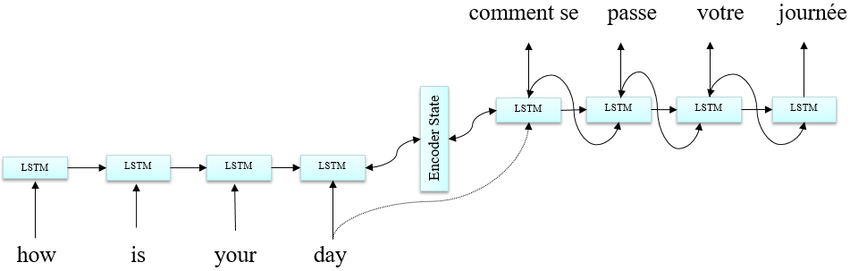
More recently, deep neural network models have achieved state-of-the-art results in a field that is aptly named Neural Machine Translation. Most Neural Machine Translation systems follow the encoder-decoder architecture where the source sentence is encoded into a constant size vector using a Recurrent Neural Network as shown below and fed into another decoder network along with words from the input sentence. The constant size vector provides the required contextual information to

The above architecture, however, fails when the length of the sentence increases beyond a certain limit. This happens because we are trying to cram variable amount of contextual information into a fixed sized vector. In order to overcome this, we use Attention Mechanism.
Attention allows the decoder network to “focus” on a different part of the encoder’s outputs for every step of the decoder’s own outputs. First we calculate a set of attention weights. These will be multiplied by the encoder output vectors to create a weighted combination. The result should contain information about that specific part of the input sequence, and thus help the decoder choose the right output words. Calculating the attention weights is done with another feed-forward layer, using the decoder’s input and hidden state as inputs.

Translating Python Code to Pseudocode
Due to its robust and flexible nature, with the extensive use of special characters with significant meaning, translating Python code to Pseudocode is much more complex than a simple language-to-language translation.
Here, to take care of the syntax and use of characters such as [, {, /, // etc., we have used a rule-based architecture to generate an Abstract Syntax Trees to provide linguistic context to the encoder. This, not only helps to simplify the model which would otherwise have to be very detailed to catch the different comprehensions and shorter notations, but also allows us to use a Neural Machine Translation model to translate the code to pseudocode.
We then use an Encoder network to read through the input code and generate an Abstract Syntax Tree. The Encoder network is trained to learn the structure of the code and the meaning of the code. It is then used to generate a sequence of hidden states which are then fed into a Decoder network to generate the pseudocode.
The Decoder network uses an Attention-based mechanism to combine the encoder output with the decoder input. The decoder network uses the encoder output to predict the next word in the input sentence and generate the output pseudocode for a given instance of Python code.
Comparing NMT Model to Existing Implementations
While the NMT model has the potential to outperform existing implementations like the Rule Based Translator or the Statistical Machine Translation Approach, the lack of training data makes it hard to accurately evaluate our implementation and compare it to existing implementations.
Conclusion
- Various Machine Translation methods were explored during the learning phase of the project
- Neural Machine Translation proved to be the superior method of translating one natural language to the other
- For the problem statement of generating English psuedocode from Python code, we propose to use Tree-LSTM or Tree-GRU models to improve syntacic context to the machine translation model