Mentors
- Jason Kritik Kumar
- Shreya Shaji Namath
- Sidharth Lanka
Members
- Harish Gumnur
- Vaishali S
- Vinayak Vatsalya J
Aim
To inpaint the missing features in the given input image through the use of Generative Adversarial Networks.
Introduction
Image inpainting is the process of reconstructing missing parts of an image so that observers are unable to tell that these regions have undergone restoration. This technique is often used to remove unwanted objects from an image or to restore damaged portions of old photos.


GANs can extract high-level semantic characteristics and have powerful learning capabilities. These characteristics can be used to semantically fill up gaps. The structural consistency and texture clarity of an ideal image restoration must be maintained. To improve prediction accuracy, we have used an inpainting method that may synthesize unique image structures and explicitly use surrounding image attributes as references during network training.
GANs
A generative adversarial network (GAN) is a class of machine learning frameworks which create new data instances that resemble the training data i.e “generative” . GANs learn in a unique way, they are composed of two neural networks: The Generator and The Discriminator. The generator model generates new instances of training data or in our case, images of faces. We provide input to the generator and this input is known as “noise”. Noise is usually a randomly generated vector and we obtain a different image by changing the noise vector. The generator then transforms this noise into a meaningful output. By introducing noise, we can get the GAN to produce a wide variety of data, sampling from different places in the target distribution. Experiments suggest that the distribution of the noise doesn’t matter much, so we can choose something that’s easy to sample from, like a uniform distribution. The discriminator model, as the name suggests, tries to classify examples as either real (from the training set) or fake (generated). The two models are made to compete against each other (this is known as adversarial). So the objective of the generator is to fool the discriminator into thinking that the image created by it is real.
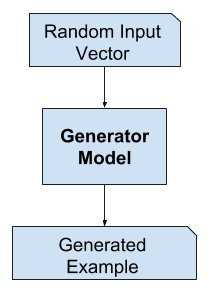
Generative Training
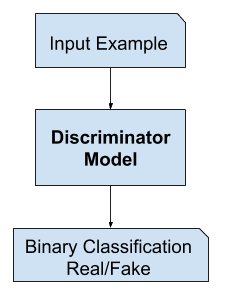
Discriminator Training
When we combine both the generator and discriminator we get:
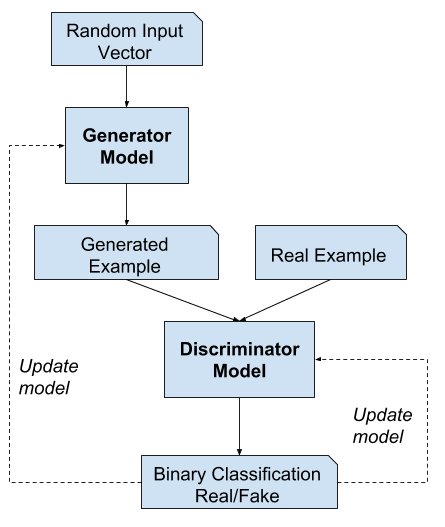
They are trained together until the discriminator model cannot tell the fake images from real, and this means that the generator model is generating “plausible” examples. The generator learns(updating weights) from the discriminator’s feedback, this is known as backpropagation. Backpropagation adjusts each weight in the right direction and calculates how the output would change if you changed the weight. But the impact of a generator weight depends on the impact of the discriminator weights it feeds into. Generative models try to tackle a more difficult task than discriminative models. A generative model for images would have to capture correlations like “cars are usually on roads” and “nose is at the center of the face.” These are very complicated distributions and this explains why training the generator is harder than the discriminator. So at the start of the training process, the generator learns very slowly compared to the discriminator. GANs can not only be used for generating images, they can also be used to generate new audio samples, essentially any new data instance.
Our model architecture
Our framework consists of a generator and a discriminator with two branches, as shown in the diagram below. The discriminator conducts adversarial training, while the generator generates believable painted results.

For image inpainting task, the size of the receptive fields should be sufficiently large. Large convolution kernel (e.g.7 × 7) is applied in some of the earlier approaches to implement this. This technique, however, introduces a lot of model parameters. We have used a dense multi-scale fusion block to concurrently increase receptive fields and assure dense convolution kernels.

In DMFB, the first convolution on the left decreases the channels of input features to 64 to reduce the parameters, and then these processed features are passed to four branches to extract multi-scale features, indicated as xi I = 1, 2, 3, 4) using dilated convolutions with various dilation factors. Except for x1, each xi has a 3 3 convolution, which is indicated by Ki (). We can acquire dense multi-scale features by combining several sparse multi-scale features in a cumulative addition method.
The fusing of concatenated features is then performed using a 1x1 convolution. In a nutshell, this fundamental block improves generic dilated convolution and has fewer parameters than huge kernels.
Unlike earlier generative inpainting networks that use WGAN-GP for adversarial training , this one is a bit different. We have used RaGAN to pursue greater photo-realistic results. Our discriminator also takes into account the Image consistency on a global and local level.
Dataset used
The dataset being used in our project is the CelebFaces Attributes also known as the CelebA Dataset. As the name suggests, it is a large scale face attributes dataset consisting of celebrity faces. Images cover large pose variations, background clutter, diverse people, supported by a large quantity of images and rich annotations. making it a popular dataset used in computer vision tasks. A popular component of computer vision and deep learning revolves around identifying faces for various applications from logging into your phone with your face or searching through surveillance images for a particular suspect. This dataset is great for training and testing models for face detection, particularly for recognising facial attributes such as finding people with brown hair, are smiling, or wearing glasses.
This data was originally collected by researchers at MMLAB, The Chinese University of Hong Kong. The creators of this dataset wrote the following paper employing CelebA for face detection: S. Yang, P. Luo, C. C. Loy, and X. Tang, “From Facial Parts Responses to Face Detection: A Deep Learning Approach”, in IEEE International Conference on Computer Vision (ICCV), 2015,
The dataset consists of
- 202,599 number of face images of various celebrities
- 10,177 unique identities, with no labels
- 40 binary attribute annotations per image
- 5 landmark locations
The reason for not choosing other popular datasets such as cifar, fashion mnist or places is due to them having too wide a range of types of images to train on, thereby making it potentially harder and infeasible for our model to train on given the time and resources. By limiting the training data to similar Structures of faces as seen in the CelebA dataset, the model can learn faster since all the images fall within a certain set of boundary conditions. Despite the large number of variations as seen in the faces, the base structure is similar. One of the major reasons for choosing this dataset is because it can show us the true power of GANs whereby it can fill in some features(inpainting the image) such as a missing eye or nose, which cannot be accomplished by other inpainting algorithms such as patchmatch. However, patchmatch does a visually decent job when it comes to images of patterns and sceneries.
Results

Conclusion
- As seen from the above results, the model learns to fill in masked out missing portions of facial images
- With further training and optimization that have been proposed in the literature such as use of contextual attention, the model’s visual accuracy can be greatly improved.