A new class of Generative Models was proposed in 2014 by Ian Goodfellow (a.k.a The GANfather) which brought in a novel method of dealing with issues in ML and AI. The Invention of Generative Adversarial Networks (GANs) can be regarded as one of the path-breaking innovations in making computers do useful stuff. GANs have seen some crazy development from an application perspective and has been one of the hottest topics for research in the past 5 years.
So what does a Generative Model do?
The main objective of a Generative Model is to create more samples of the same type as training data. The basic idea is to take a set of training examples and develop a probability distribution. Based on that distribution, it generates more samples. There are two ways of generative modeling - one is to explicitly define a density function, for instance, a Gaussian density function or log-likelihood which tells the probability distribution that generated them and the other is observing many samples from a particular distribution and generating more samples from the same distribution. GANs come under the latter category, where learning the function is left to the model itself.
How do GANs work?
GANs form a subclass of implicit Generative models that rely on adversarial training of two networks: the Generator G, which attempts to produce samples that mimic the reference distribution, and the Discriminator D, which tries to differentiate between real and generated samples and, in doing so, provides a useful gradient signal to the Generator. GANs have proven to be useful in various domains like unsupervised feature learning, image and video generation. They are illustrated with an analogy in the image.
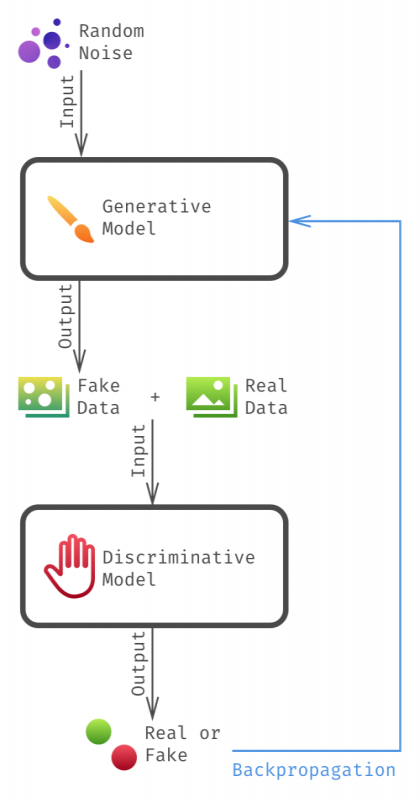
Why are Generative Models useful?
The first question that comes to mind is that why do we even care about generating more samples (say images) with tons of them lying around? The applications are pleasing enough to reason for it:
- Generative models can be used in Curiosity-driven Exploration in Deep Reinforcement Learning. One of the biggest problems in RL is balanced Exploration and Exploitation in high dimensional space. Without efficient Exploration techniques, the agent may just wander around until it stumbles into a rewarding state. This can waste a lot of computation and training time even if we use a heuristic approach. In this paper, Rein Houthooft and colleagues propose VIME, a practical approach to exploration using uncertainty on Generative models.
The following illustration compares the two approaches. The agent in the left is trained using VIME approach while the right one using Naive approach.
 |
 |
-
We can use Generative models to simulate possible futures for Reinforcement Learning. We can have an agent learn in a simulated environment built entirely using generative models rather than building it physically. The advantage of using this model-based RL approach is that it can be parallelized easily across different machines and the mistakes in it are not as costly as if we make them in the real world.
-
Generative models can to fill in missing inputs and learn even when some of the labels in the data are missing. They handle missing inputs much more effectively than the traditional input to output mappings in machine learning models. GAINs are a type of GANs where the generator imputes a vector of real data, which is then fed back to the discriminator to figure out which data was originally missing. MisGAN is another variety that can learn from complex, higher-dimensional incomplete data using a pair of generators and discriminators. Semi-Supervised Learning is an application where we may have very few labeled inputs but by leveraging many more unlabeled examples, we can do good on the test set.
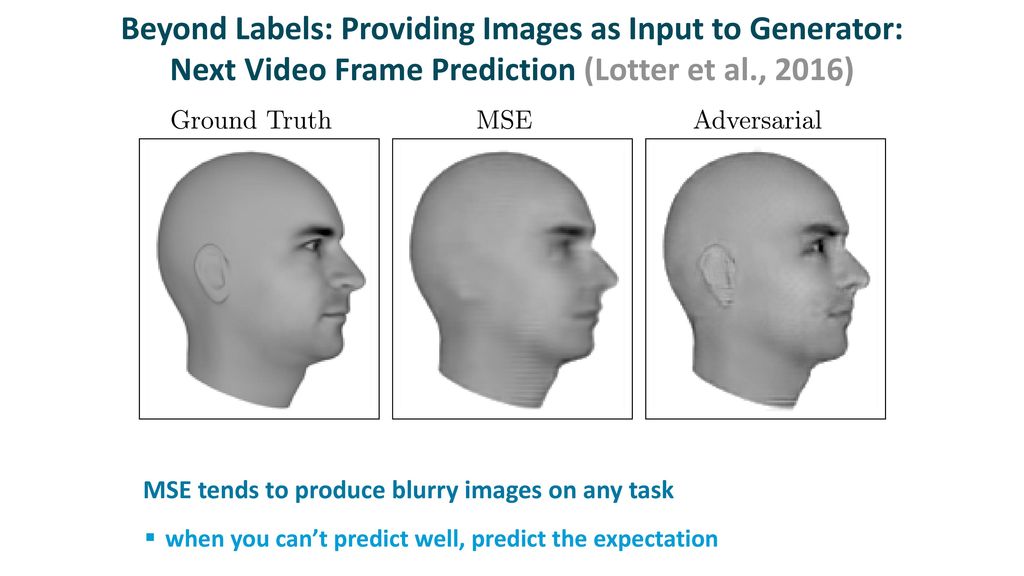
- The picture shows two approaches to finding the next frame in the video. Since there are many possibilities in a video in the next time step, traditional approaches like Mean Squared Error (MSE), result in the output being a bit blurry as a consequence of averaging out various results. Using generative techniques and adversarial particularly results in getting a sharp output towards the eyes as well as ears.
GANs Demystified…
GANs are turning out to be better than the traditional approaches in various applications of Machine Learning. Following are some of the recent developments in GANs:
High Fidelity Speech Synthesis with GANs
The Text-to-Speech (TTS) task consists of the conversion of text into speech audio. There has been a lot of development in this field using Neural Autoregressive models. However, an essential disadvantage of this technique is that it is difficult to parallelize. Every time step in the audio needs to be considered sequentially which is computationally expensive.
Using GANs can help in parallel waveform generation. GAN-TTS, a Generative Adversarial Network for Text-to-Speech is a novel architecture proposed for this. It consists of a feed-forward generator, which is a Convolutional Neural Network, paired with an ensemble of multiple discriminators which evaluate the generated and real data. Mean Opinion Score (MOS), as well as quantitative metrics - Frechet DeepSpeech Distance and Kernel DeepSpeech Distance, are used as evaluation metrics.
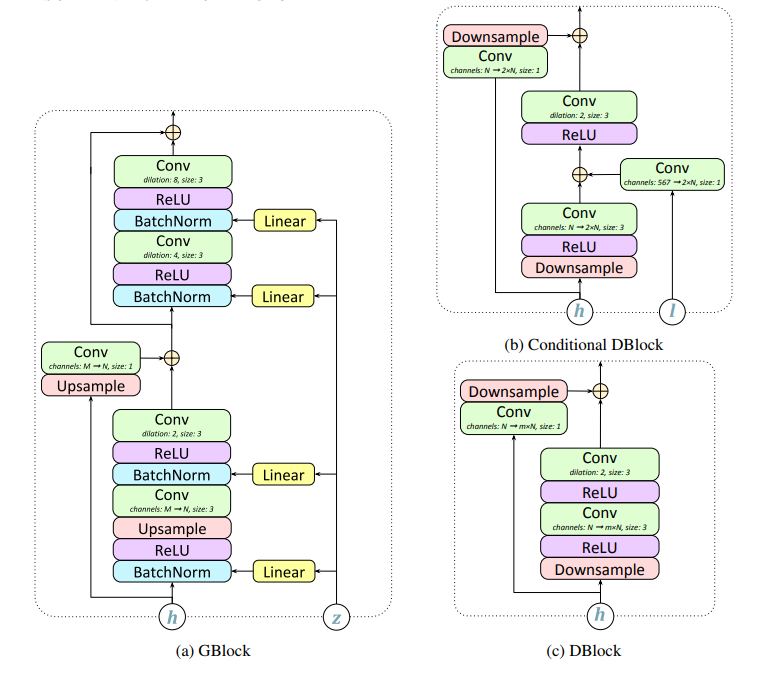
The generator’s input is pitch and linguistic features and output is a raw waveform at a certain frequency. GBlock shows the design of the generator in the above diagram. The output convolutional layer uses tanh activation function to produce a single-channel audio waveform. The discriminator consists of an ensemble instead of a single model as in DBlock. Some discriminators take the linguistic conditioning into account while others ignore the conditioning and can only assess the general realism of the audio.
Connecting GANs and Actor-Critic methods in RL
Both GANs in unsupervised Learning and Actor-Critic methods in Reinforcement Learning are difficult to optimize and stabilize since they often end up giving degenerate solutions. Both are multi-level optimization methods where we do not have a single unified objective function and consist of hybrid models where each tries to minimize its private cost function. Each level is optimized with respect to the optimum of the other model. This makes the traditional optimization methods like Gradient Descent and its variants not work very well since they are oriented towards solving a common cost function.
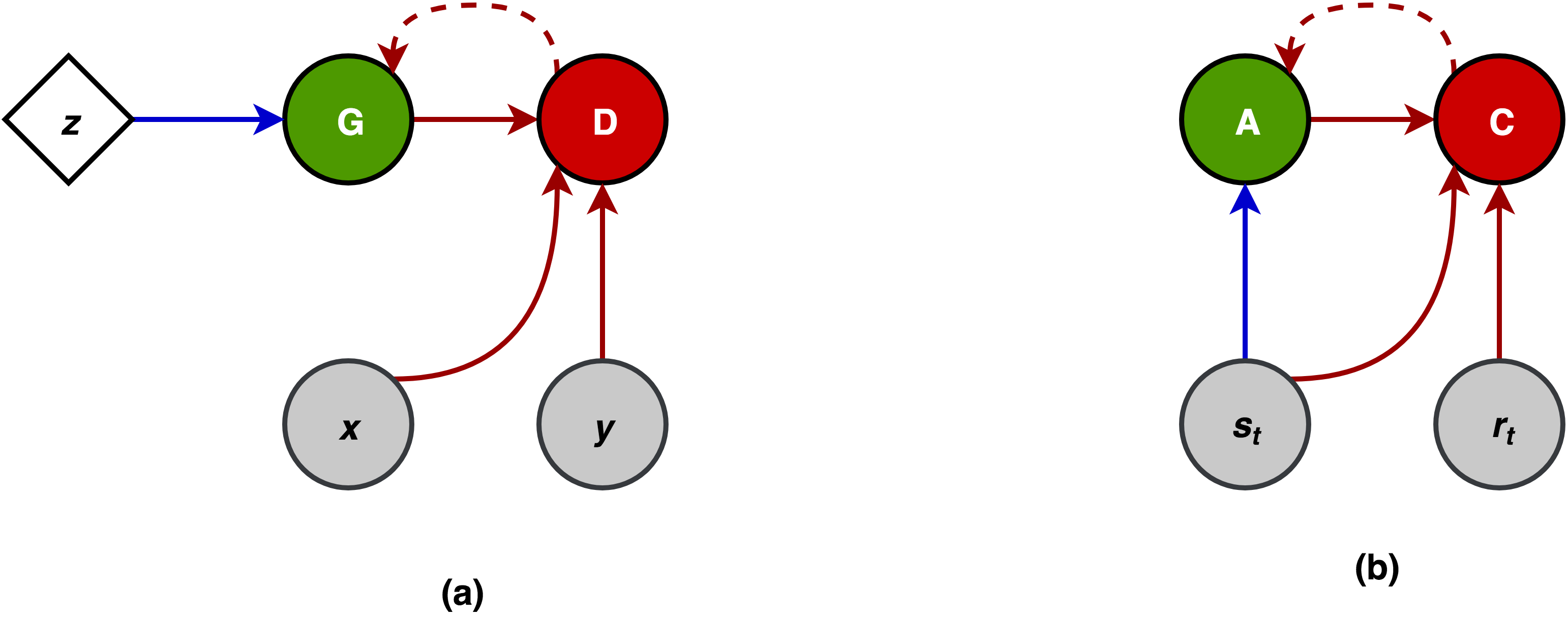
The main aim of AC methods is to simultaneously learn an action-value function along with a policy, thereby predicting the reward, while GANs learn to produce more samples of the same type as training data. Both have a feed-forward propagation step where one model controls the agent’s behavior (Actor A) or generates samples (Generator G) and the second evaluates how good the action is (Critic C) or classifies samples as fake or real (Discriminator D). The second model has access to some additional information from the environment - reward in case of AC and real data samples in case of GANs. These similarities suggest that heuristics and optimizations for one can be applied for the other.
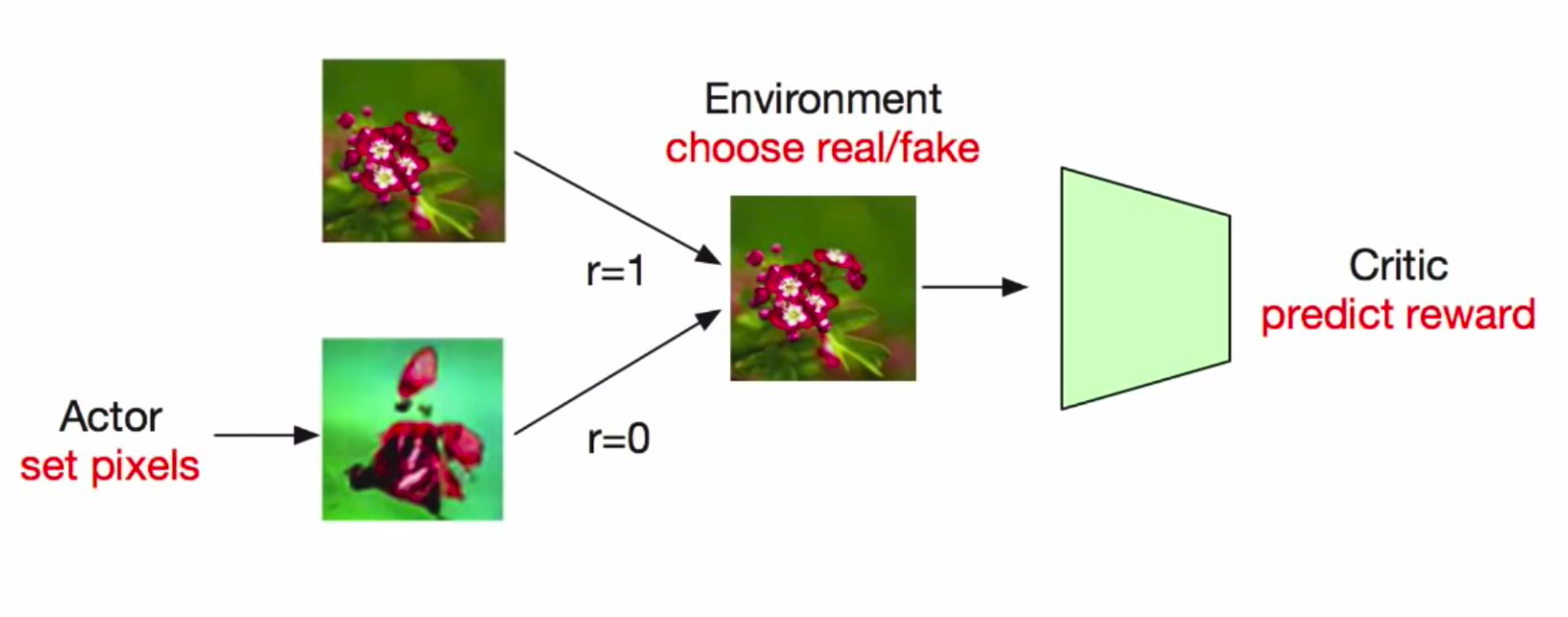
The GAN minimax game can be thought of as an agent-environment set up where the actor chooses to set pixels of the image. The environment then stochastically chooses to show a real image and give reward 1 or show the actions and give reward 0. The critic has to predict what the reward is. Here the actor never actually sees the true environment analogous to the generator in GANs where it does not see the real data samples. They rely only on the gradient signal given by the other model. However, this is a sort of unusual setting where the actor does not get to influence the reward, hence making both components adversarial instead of cooperative.
GANs in Medical Imaging
GANs have received state-of-art performance in many image generation tasks. Their ability to create more data without explicitly learning probability density function has a huge scope in Computer Vision. There are two ways in which GANs can be applied in medical imaging. One is the use of a trained generator model to generate images of various body parts. Other is that the discriminator, trained on normal images can be used as a regularizer or detector for abnormal images. GANs have an edge over traditional ML approaches in medical imaging in terms of cell structure exploration and detecting abnormalities.
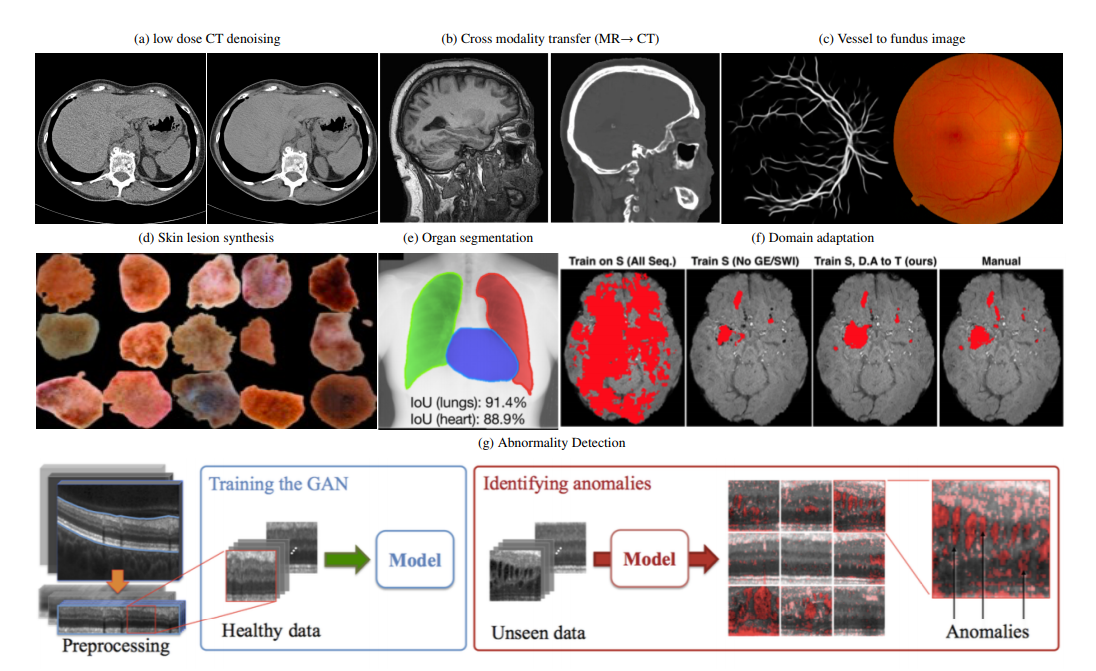
Reconstruction is a major issue in medical imaging. Many times the image and scans obtained might have some noise or blurriness associated with it. This can be due to various reasons like patient comfort, constraints in clinical settings, etc. A pix2pix framework and pre-trained VGG-net have been used to solve the problem but appreciable results are difficult to achieve in case of pumping organs like the heart. The use of CycleGAN has achieved improvement in cardiac CT denoising.
GANs have also been used for classification tasks in medicine. The semi-supervised training scheme of GANs for chest abnormality detection and cardiac disease diagnosis has achieved comparable results with the original supervised CNN approach with considerably less labeled data.
Liquid Warping GANs
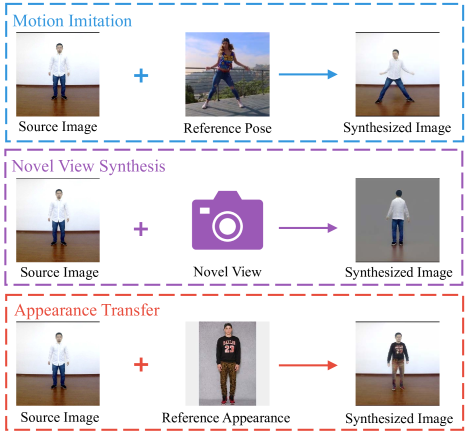
Liquid Warping GAN is a unified approach towards Human Motion Imitation, Appearance Transfer, and Novel View Synthesis. These techniques are extremely useful in animation, video and game making, virtual clothes try-on, etc. Previous works separately handled these tasks with specific pipelines. Recently, GANs have proven to be useful in successfully solving all three tasks together. Motion imitation inputs a source image and a reference pose image and outputs the person in the former with a pose in the latter. Appearance Transfer is quite similar to Neural Style Transfer in Computer Vision, where the aim is to produce a human image preserving the reference identity with clothes (style). Novel View Synthesis aims to produce images of the person from different angles and views.
As in many Computer Vision applications, traditional methods use 2D landmarking techniques to predict human body structure. However, these can capture only positional details with no modeling of limb rotations and characterization of body shape, which makes the output a bit less realistic. Using Liquid Warping GANs, we can capture the 3D body mesh and simultaneously preserve texture, color, style, and other finer details.
The pipeline consists of 3 stages which are same for all the three tasks:
Body Mesh recovery
In this module, the basic body structure, shape and 3D mesh of the person in source and reference images are reconstructed using Human Mesh Recovery (HMR) which involves parsing of the image into a feature vector using ResNet-50 followed by a regression network which predicts pose and shape. A bunch of parameters calculated as a function of pose and shape is passed to the next module in the pipeline.
Flow Composition
This step involves the construction of a map of the source and reference mesh followed by calculating the weighted geometric centroid coordinates of each mesh face. A transformation flow vector T is obtained and warped with the source image to get the warped image.
Liquid Warping GAN
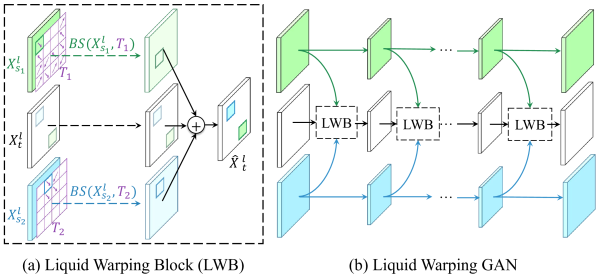
This stage focuses on producing high-fidelity images with desired conditions like style, texture, etc. We use Liquid Warping Block (LWB) to preserve these conditions.
-
Generator: The generator works as 3 streams. The first stream of GANs works on generating a realistic background image. The second or source identity stream is a convolutional auto-encoder that identifies the source content, extracts the features required to keep the source details and reconstructs the source front image. The third or the transfer stream synthesizes the final result. LWB links the latter two streams. Advantage of using LWB is that it takes care of multiple sources, like in Appearance Transfer, preserving the head of source one and wearing the upper outer garment from the source two, while wearing the lower outer garment from the source three.
-
Discriminator: For discriminator, a pix2pix model is followed.
References
