Introduction
A trie is a rooted tree that maintains a set of strings. Each string in the set is stored as a chain of characters that starts at the root. If two strings have a common prefix, they also have a common chain in the tree. Consider the following set of strings {canal, candy, there, the} and let us make an example trie from these.
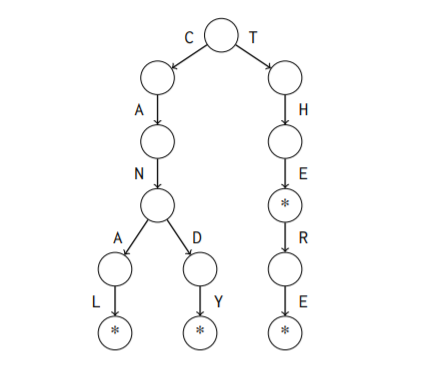
The * character in the node means that a string in the set ends at that node. Such a distinction is needed because a string may be a prefix of another string like “the” is of “there”.
The 2 basic operations of a trie is search and insert :
Search - We can check if a trie contains a string of length n in O(n) time because we can just follow the corresponding chain starting from the root and suppose a character in that string is not present in the trie then it means that string does not exist.
Insert - We can also insert a string of length n in O(n) time by initially following the chain till the longest matching prefix available and then adding nodes as necessary. So in the end the extra nodes that we will have to insert are just the ones not in the longest matching prefix.
The size of a trie is equal to the number of distinct prefixes of all the strings in the set. The height of a trie is defined as the length of the longest string in the set.
Applications
Trie is an incredibly useful data structure for many real life applications which are based on string processing and handling. Some examples are given below:
Auto Complete - One could say autocomplete is the most useful application of trie. It is a process through which the software predicts the rest of the word a user is typing based on the string prefix. It helps to optimize search engine results and also improves the user experience. Various software applications such as web browsers, command line interpreters, email, database query tools and others use autocomplete. To improve the quality of the suggested words we can store additional information like a key value and prefer those words with the same prefix that have a history of being used more often, this is similar to browser history.
Spell Checkers - Trie is used to store the data dictionary and can check for the word in the dictionary and if it is not present then generate potential valid suggestions of words that can be constructed instead. Then sort these suggestions with the higher priority ones on top and present it to the user.
DNA Sequencing - It is used to store and process large DNA sequences and search for matching patterns present in it. Since this process requires significant computation and memory a trie is quite an efficient data structure for this.
PseudoCode
Trie Node Structure
struct TrieNode
{
struct TrieNode *children[26];
bool is_end;
TrieNode()
{
is_end = false;
for(int i=0; i<26; i++)
children[i] = NULL;
}
};
struct TrieNode *root;
Insert Operation
void insert(string key)
{
struct TrieNode *pwalk = root;
for(int i = 0; i < (int)key.length(); i++)
{
int index = key[i] - 'a';
if(!pwalk->children[index])
pwalk->children[index] = new TrieNode();
pwalk = pwalk->children[index];
}
pwalk->is_end = true;
}
Search Operation
bool search(string key)
{
struct TrieNode *pwalk = root;
for(int i = 0; i < (int)key.length(); i++)
{
int index = key[i] - 'a';
if(!pwalk->children[index])
return false;
pwalk = pwalk->children[index];
}
return pwalk->is_end;
}
Improving efficiency of a solution using Trie
Consider the problem where we need to find the maximum value xor pair in an array of numbers.
The Naive approach would be to calculate the xor value of all pairs of numbers in the array and then find the maximum value out of it. However this is not very efficient as the time complexity is O(N^2).
Here we can use trie to store the binary representation of each number in the array and then we search for each number the maximum xor value we can get by taking the path opposite to the value of that bit in the number. Suppose the current bit is 1 then we look for a path with the bit set to 0 and we take the path with the opposite bit as long as it exists. In this manner for each number we will end up with the maximum value xor pair it can form and then take the maximum of these values.
Comparison with other data structures
Trie and hash tables are used in many similar applications. There are many advantages of a trie over a hash table : There are no collisions of different keys in a trie. Because of the above property the worst case look up time in a trie is better ( O(length) ) than hash table which can be ( O(n) ) due to collisions. Best case for both is the same ( O(length) ). Trie provides an alphabetical ordering of entries. Trie does not require buckets unless a single key is associated with more than one value.
There are some drawbacks also for trie in comparison to hash table: They require more memory for storing strings. When keys are floating point numbers it can lead to long chains that are not really meaningful. However this can be handled by using a variant of trie called bitwise trie.
Here is a list of some resources to get a better understanding of trie and also some common interview problems.
