Merkle Trees and their application in Git
In computer science, Merkle trees are a hash-tree data structure used for data validation and synchronization.
Lets break this down. It is essentially a tree data structure but instead of storing the data (like we do when we want to represent a heirarchial data), merkle trees are special trees which store the hash values of data. By hashes, I am talking about cryptographic hashes. Before getting into merkle trees, what they are and how they work, it is important to understand what hashes are and how they work.
Hashes
Hashing is simply the process of passing some data through a formula that produces a result. Well then, what is sooo speacial about it?? Well..
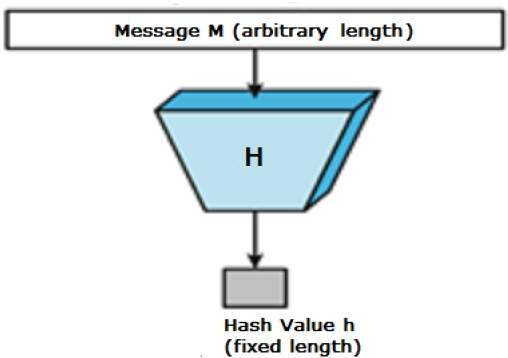
Hash functions are one way mathematical functions that convert a given piece of data into another form (like encoded data). It is this one way property that makes it unique. It acts as a “digital fingerprint” for a piece of data. Hash functions are designed in a way that there is very little probability that another piece of data will also result in the same hash. Another interesting and useful property of hash functions is that they are pseudo random, i.e., even a small change in the data (say addition or removal of a letter) will result in a completely new and a random looking string, which makes it nearly impossible to reverse enginner the hash to get back the input data. This is really useful in cryptography when you want to check for the integrity of data.
If you want to play around with hashes, check this out!! SHA 256 hash calculator
Merkle Trees
After construction, a Merkle Tree looks something like this:
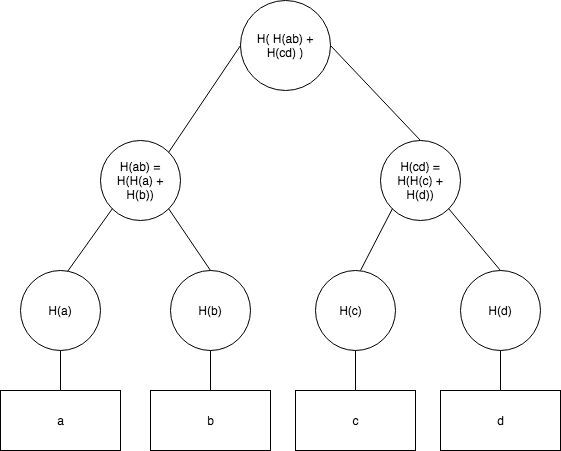
a, b, c, and d are some data elements (files, public/private keys.. etc) and H is a hash function.
Each node is created by hashing the concatenation of its “parents” in the tree. For eg: H(ab) is formed by concatenating its “parents:, H(a) and H(b).
Note: In general and in most use cases, merkle trees are binary trees, but it is not a restriction.
The tree is constructed by taking nodes at the same height, concatenating their values, hashing the result and recursively performing this operation until the root is reached.
Once built, data can be audited (checked for) using only the root hash logarithmic time to the number of leaves (also called a Merkle-Proof). When we are auditing data, what we are essentially doing is checking if a given piece of information is a part of the merkle tree or not? It works by recreating the branch containing the piece of data from the root to the piece of data being audited. In the example above, if we wanted to audit c (assuming we have the root hash), we would need to be given H(d) and H(H(a) + H(b)). We would hash c to get H(c), then concatenate and hash H(c) with H(d), then concatenate and hash the result of that with H(H(a) + H(b)). If the result was the same string as the root hash, it would imply that c is truly a part of the data in the Merkle Tree.
Applications
Ever since it was introduced in 1979, Merkle Trees have gotten a lot of attention. They are used in many systems that use distributed architectures like
- Blockchain
- Git
- BitTorrents
- IPFS
In many peer-to-peer (P2P) systems, individuals need to be able to request data from untrusted peers with some proof that what those peers sent them is part of the real content they requested. Torrents are a very good example of this, where in another peer would provide the piece of data, and you need to be sure of the integrity of the data you recieved.
In the merkle tree example shown above, what this means is that if you asked for “c”, you rebuild the merkle path and check if your result is the same as the root hash. If it is, you can be really confident of the integrity of the data. If you’re concerned about the security of this approach, recall that in a hash function it is computationally very difficult (nearly impossible) to find some x such that H(x) = H(c). This means that if the the root hash is correct, you can be really confident that the data you recieved is indeed what you asked for!!
In this blog, I will mainly focus on the use case of Merkle Tree in Git.
Version Control, Git & Merkle Trees
If you aren’t familiar with git, you can learn it from here
Git maintains version history by maintaining a hash table in the .git folder. Hash of the object is the key, and the content is the value. A git object could be a commit, a tree, or a blob.
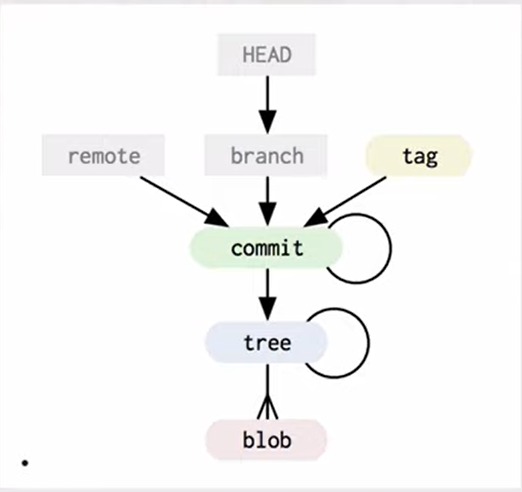 In our discussion on merkle trees, we will mainly focus on the lower half the above diagram.
In our discussion on merkle trees, we will mainly focus on the lower half the above diagram.
Every file in git is stored as a blob (binary large object). Blog is a file like object, with immutable raw data. If 2 files have the same content, then their hashes will be the same, so no new blob will be created even if the 2 files are in 2 different directories.
Every commit object has 2 reference pointers, one pointing to its parent (previous) commit and the other referencing its merkle tree root hash.
This merkle tree hash is computed by hashing all its “parent” nodes. The term “parent” might be a little misleading, but it is important to understand that 2 blobs come together (hashes are concatenated) and a new hash of the concatenated string becomes the hash of the merkle tree. So the direction is from bottom to up and not the other way.
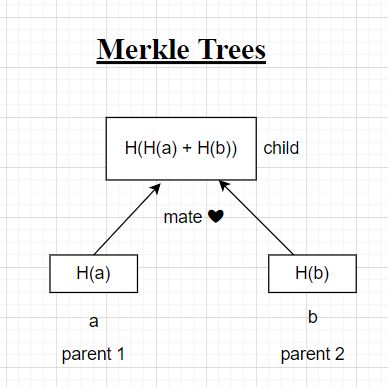
How Merkle Tree helps in versioning
As discussed earlier, blobs are raw and immutable contents, you will never find a replica of a blob in memory. To understand this, let us consider an example…
In the diagram ,blob1 in the second half of the diagram is NOT recreated, it refrences the earlier blob in memory. This is really useful in versioning because it helps save space as another complete copy of the repo need not be created, only the ones that are changed are reflected along the merkle path.
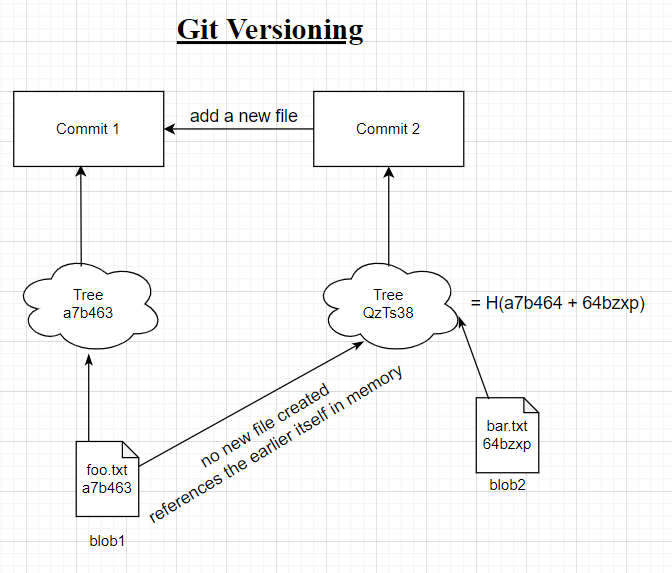
This way merkle trees are used in git to efficiently track and store versions.
Use case in Blockchain
In the case of cryptocurrencies, if someone claims that in some transaction another peer paid them, how can a node on the network verify that transaction really happened? One option is that the node could store the entire history of every transaction that has ever occurred. But this is not a good approach as it would lead to wastage of space and time and is simply not practical for large systems. Merkle Trees are a solution to this proble. By creating a Merkle Tree out of the transaction data in each block, transactions can be audited in logarithmic time instead of linear time. This opens the door for, say bitcoin clients, to save space by only storing the root of the Merkle Tree (will be able to verify any transaction in a block with just this one hash value). Not needing to store every transaction that has ever happened in the history of Bitcoin is of huge value!
The applications of Merkle Trees are indeed numerous, and their utilization in any particular domain could be the subject of an entire blog post. I hope this served as a reasonable introduction.
If you have any more questions or just want to chat, feel free to contact me at advaithcurpod@gmail.com or ping me on Twitter: @Advaith79630527
References
