“How does Google translate work? How do Alexa and Siri know what and when to respond to your queries?”
What does Machine Translation mean?
Machine Translation is essentially software that automatically renders text from one language into another. Formally speaking it falls under computational linguistics and language engineering. Machine translation needn’t just be conversion across human readable languages but can also be used for tasks like trigger word detection, converting human readable dates like ‘Tuesday, the 29th of Jan,2019’ to formats like 29-01-2019.
![]()
Various Methods of Machine Translation.
In the late 80’s, Rule-based Machine Translation, or RBMT was the initial approach for translating text. It involved following rules layed down by linguists to convert across different languages,the rules could apply at the lexical, syntactic, or semantic level. This method produced a very predictable output for a very closed domain and didn’t require a bilingual corpus (structured text data in two different languages). The problem with this was the expertise required to develop the rules, and the vast number of exceptions required. It was labour intensive and failed to perform well for real-life text.
Statistical machine translation, or SMT was a technique that was widely adopted in the industry in the early 90’s , this techinque used statistical and probabalistic models to learn to translate text from a given a source to a target language. In a paper in 1990 (A Statistical Approach to Machine Translation) the problem of translation was stated as
Given a sentence T in the target language, we seek the sentence S from which the translator produced T. We know that our chance of error is minimized by choosing that sentence S that is most probable given T. Thus, we wish to choose S so as to maximize Pr(S/T).
This technique became widely adopted since it didn’t require a set convoluted rules, exceptions and complex grammar constructs. All that was needed was sample translations of documents. This approach was completely data dependant, meaning no linguists were needed to specify any sort of rule. SMT quickly outperformed the rule-base methods and soon became the de-facto standard techinque for machine translation.
Google Translate and Bing Translator and many others still employ this technique at the core of their translation systems. Since they operate on statistics they look for patterns in hundreds of millions of documents that have already been translated by human translators. Google Translate makes special use of UN documents, which are translated in all six official UN languages, and thus provide ample linguistic data. This way, they can weigh a plethora of options for phrases presented by various different (human) translations, and select an educated guess based on the one that occurs most frequently. But statistical approaches required careful tuning of each module in the translation pipeline, and the pure data-driven approach also caused loss of syntax distinctions that could clearly be defined by linguists.
But recently, a novel approach called Neural Machine Translation, NMT has gained traction. Though this is a statistical approach, this method uses neural networks, primarily Recurrent Neural Networks, RNN to perform language translation. This method falls under Deep Learning and can learn directly, in an end-to-end fashion to translate across various langauges and all it requires is the text corpus.
Translation is achieved through just a single model that has no extra overheads.
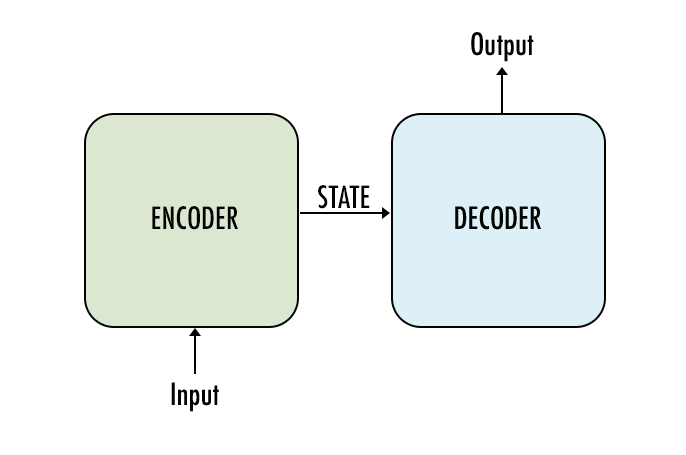
The current state-of-the art network architecture is the encoder-decoder model with an attention mechanism that has shown the best results, partly because of the availability of massive datasets and access to huge computational power.
This architecture involves encoding the input sentence into a vectorized form that the model can manipulate and decode it into another language format. This also takes care of cases where the translated sentence is of a different length than the original sentence. The attention mechanism that is in place allows the neural network to recognize the important words that are relevant for translation across different languages.
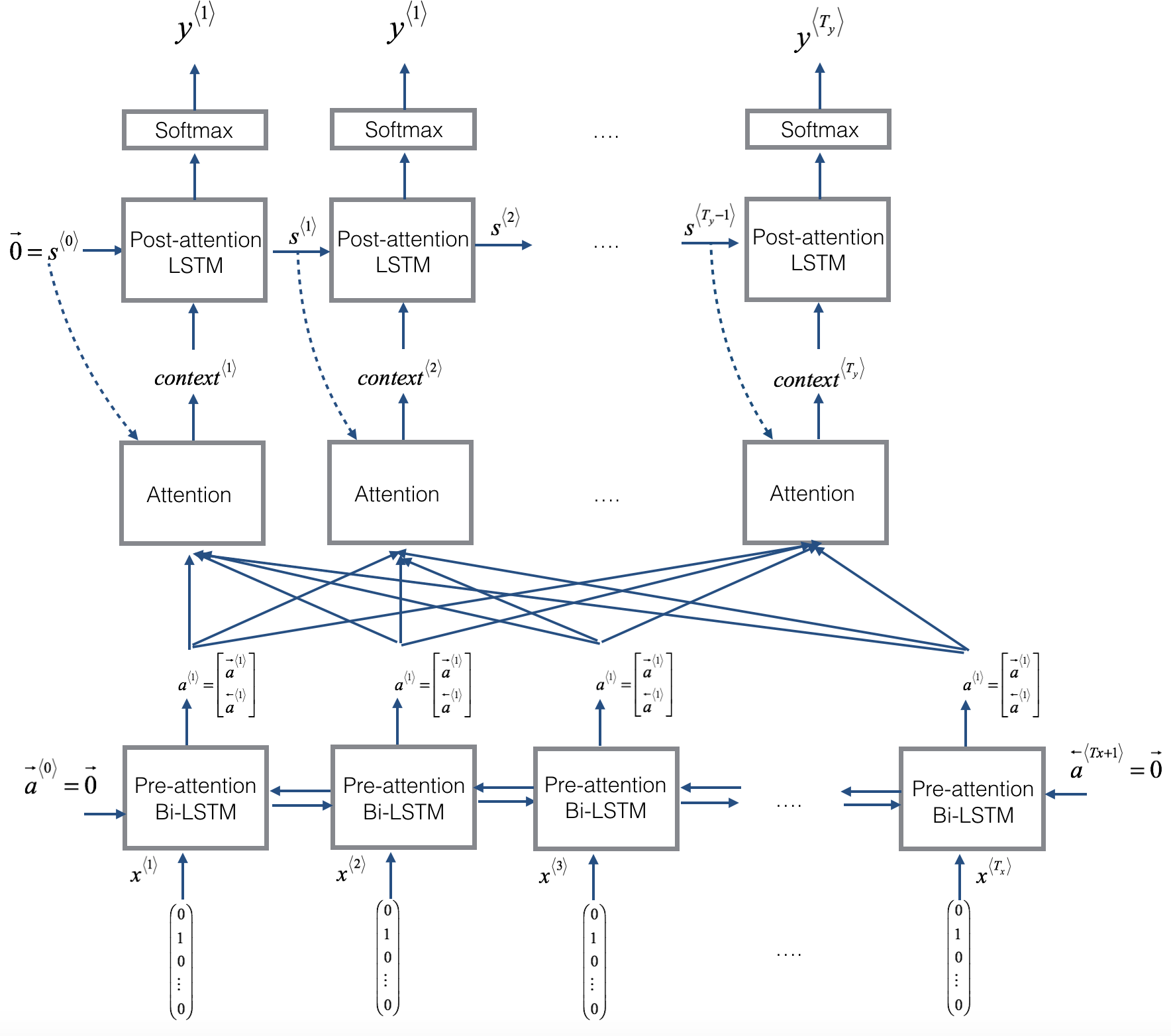
The model shown above, uses a type of RNN unit called LSTM (Long Short-Term Memory), every word in the source is passed into one LSTM unit in a sequential manner and for each word present in the input, a context vector is generated that measures the importance that must be given to that word while translating. For the encoding, the input is scanned from both directions using a Bidirectional LSTM, and once an encoding is formed decode network translates this text into another language. This allows the model to perform well on a long input sentences and be robust for different types of text.
The key to the encoder-decoder architecture is the ability of the model to encode the source text into an internal fixed-length representation called the context vector. Once this is done different decoders could be used to translate the source to different languages.
References
