Introduction
A tree is a nonlinear hierarchial data structure that consist of nodes connected by edges.
Why Trees?
Other data structures such as arrays, linked list, stack, and queue are linear data structures that store data sequentially. In order to perform any operation in a linear data structure, the time complexity increases with the increase in the data size. But, it is not acceptable in today’s computational world.
Different tree data structures allow quicker and easier access to the data as it is a non-linear data structure.
Tree Terminologies
1. Node: A node is an entity that contains a key or value and pointers to its child nodes. The last nodes of each path are called leaf nodes or external nodes that do not contain a link/pointer to child nodes. The node having at least a child node is called an internal node.
2. Edge : It is the link between any two nodes.
3. Root: It is the topmost node of a tree.
4. Height and Depth of a Node: The height of a node is the number of edges from the node to the deepest leaf (ie. the longest path from the node to a leaf node). The depth of a node is the number of edges from the root to the node.
Types of Trees
- Binary Tree
- Binary Search Tree
- AVL Tree
- Red-Black Tree
- B-Tree
There are many more types of trees which one can search and read about ;). Most common are the binary tree which have exactly two children.
Back To Competitive Programming
Common Tree Algorithms
- DFS and BFS
- Traversals
- Height of Trees and Many More
Lets talk about the DFS:
- Parent-child convention: For understanding DFS or any topic related to Tree, we use this convention, in this, we fix a root node and then we add children to it, then if the child also has a child we call it grandchild of root node and child of the node which is connected to.
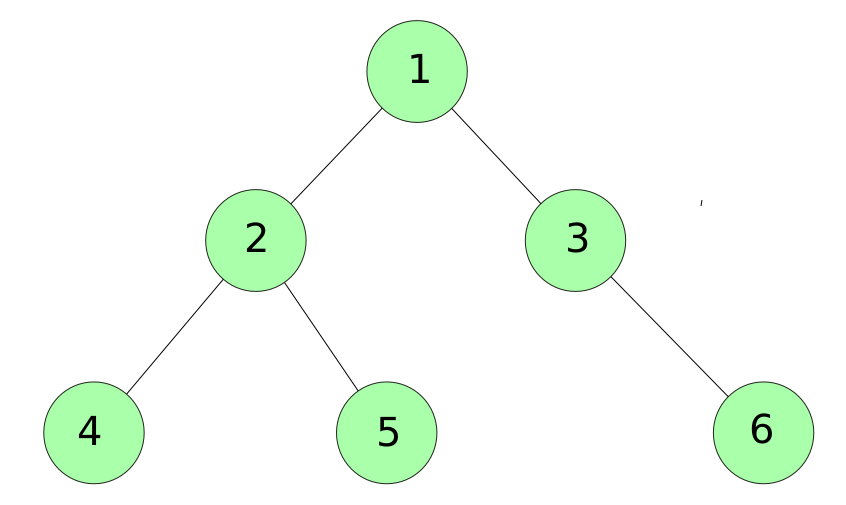
- In the above example node, 1 is the root node, node 2 and 3 are children of root 1, node 4 and 5 are children of root 2 and grandchildren of root 1, and similarly, 6 is the child of root 3 and grandchild of root 1. It is often misunderstood that a node cannot have more than 2 children.
Only in a Binary Tree, we can have at most 2 children, but in general, it’s ok if a node has more than 2 children.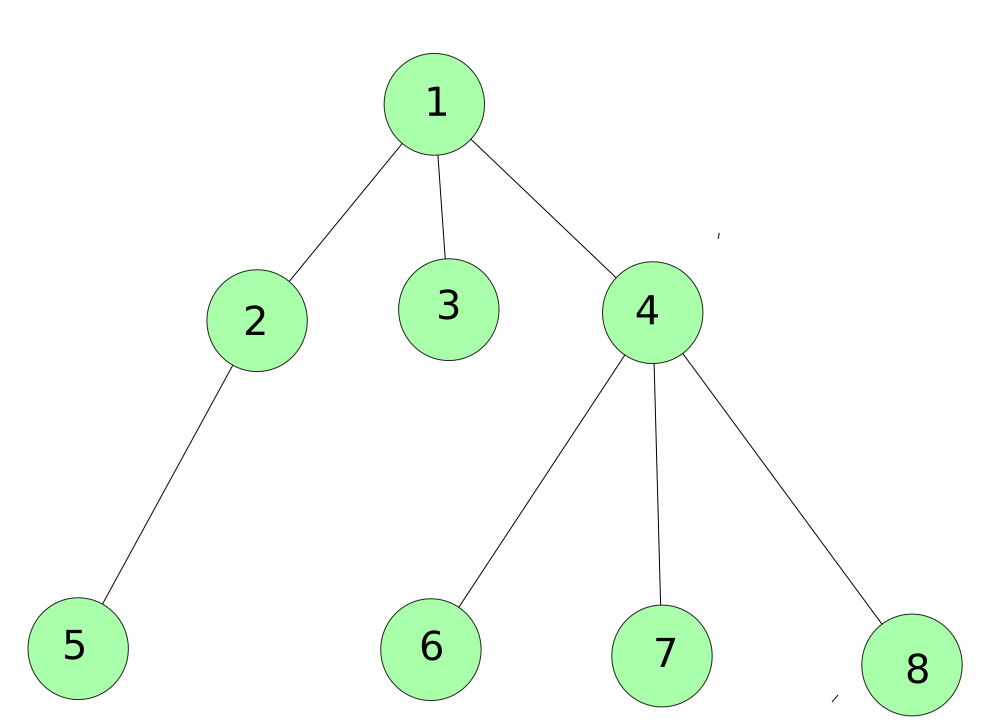
- So in the above figure , if we do dfs of root node 1, the order will be
- 1 → 2 → 5 → 3 → 4→ 6→ 7 → 8
- So overall in DFS we finish all the children before moving to the next child, and this is true for every node we visit.
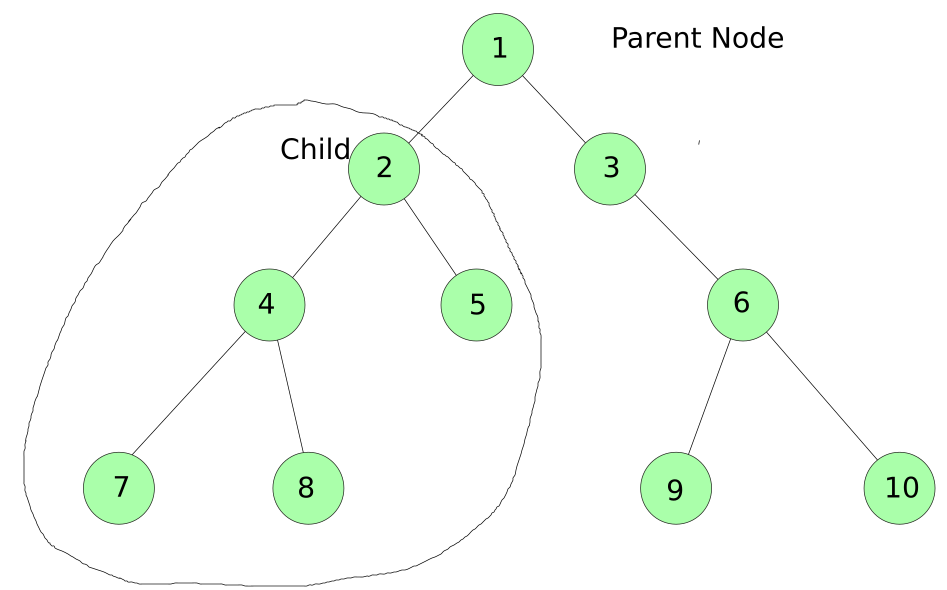
- First, 1 is Parent Node and node 2 is its child, so before visiting 3 we have to complete 2.
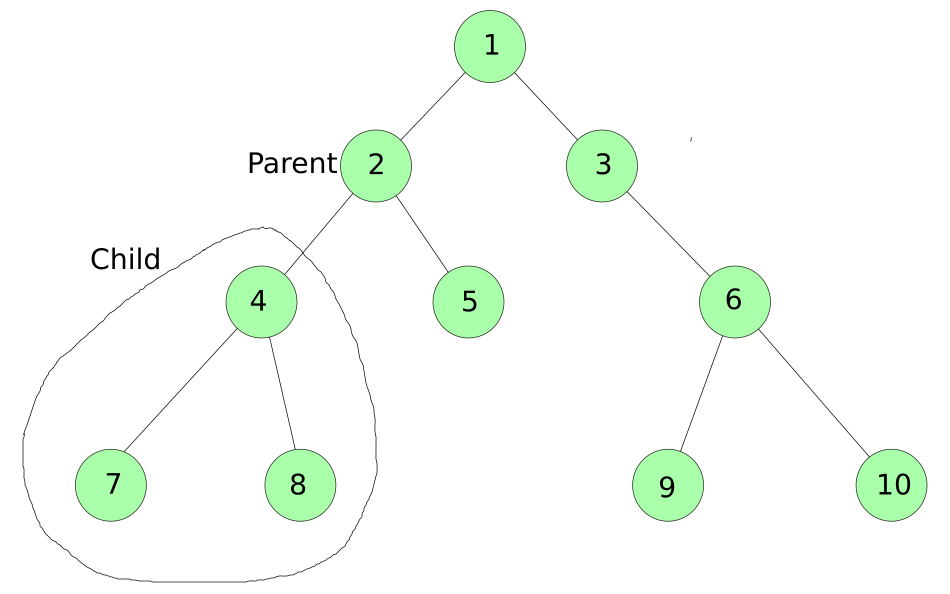
- Similarly, now node 2 is its parent node and root 4 and its children have to be completed before we visit 5. Let’s take an example:
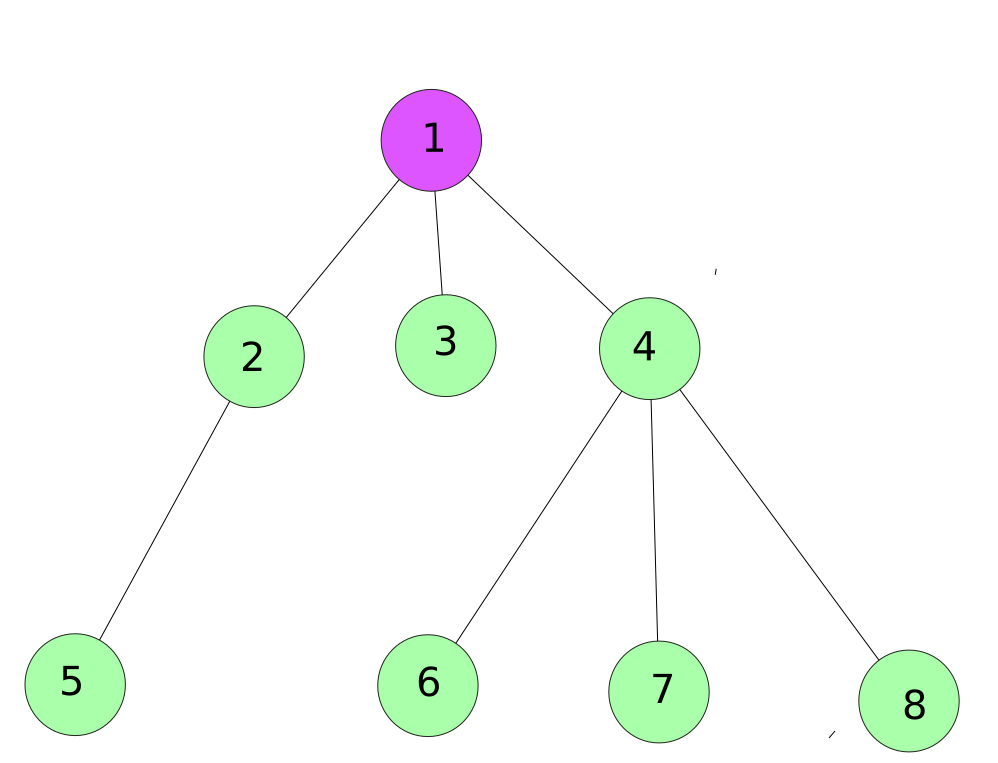 First we visit the root node.
First we visit the root node.
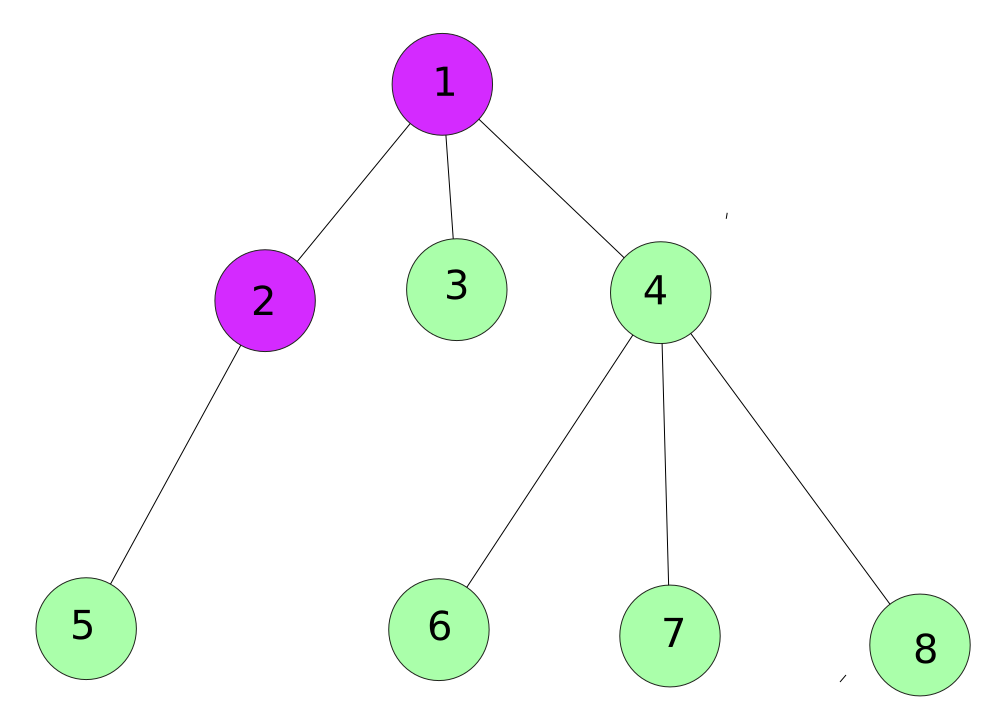 Then we move on to its first child.
Then we move on to its first child.
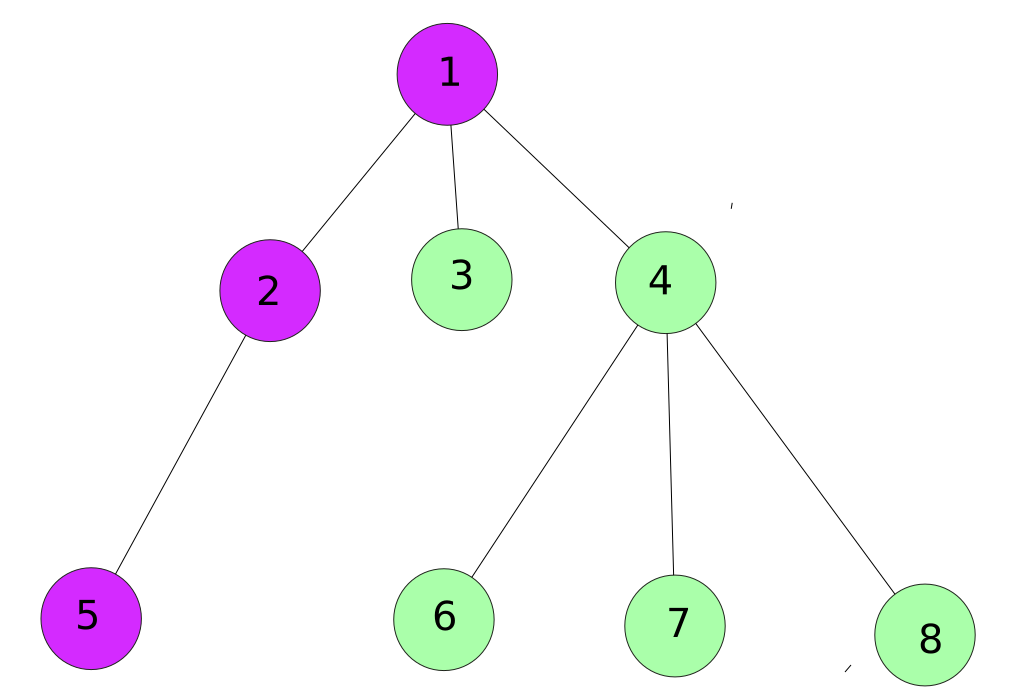 Then we visit the child of node 2.
Then we visit the child of node 2.
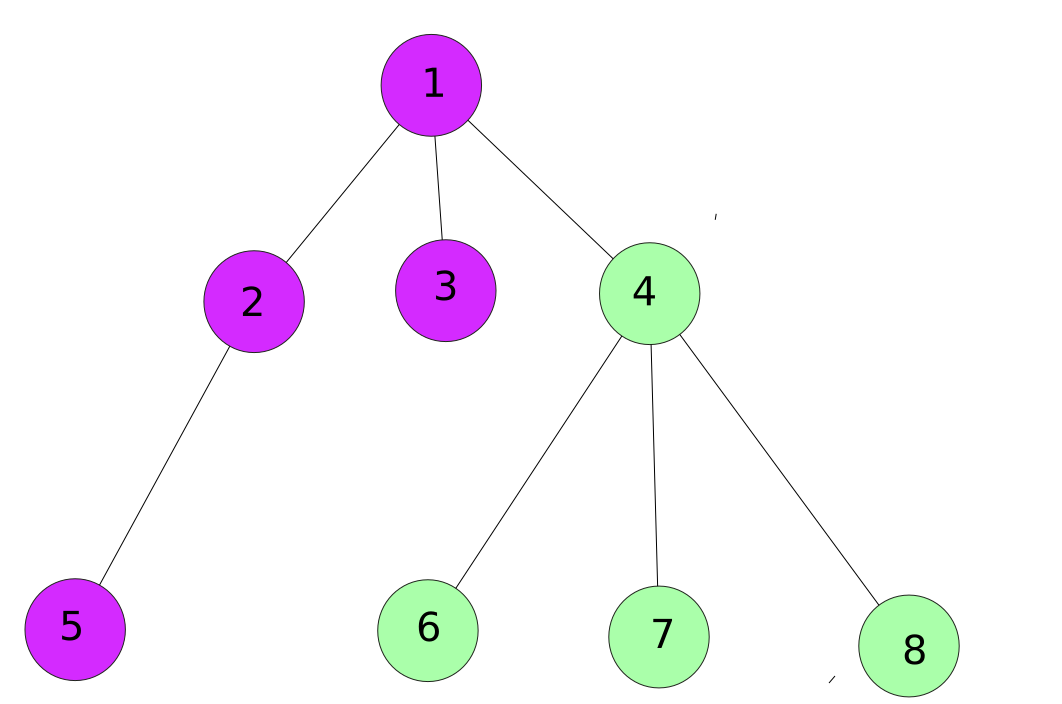 after we are done with all the children of node 2 we move onto node 3.
after we are done with all the children of node 2 we move onto node 3.
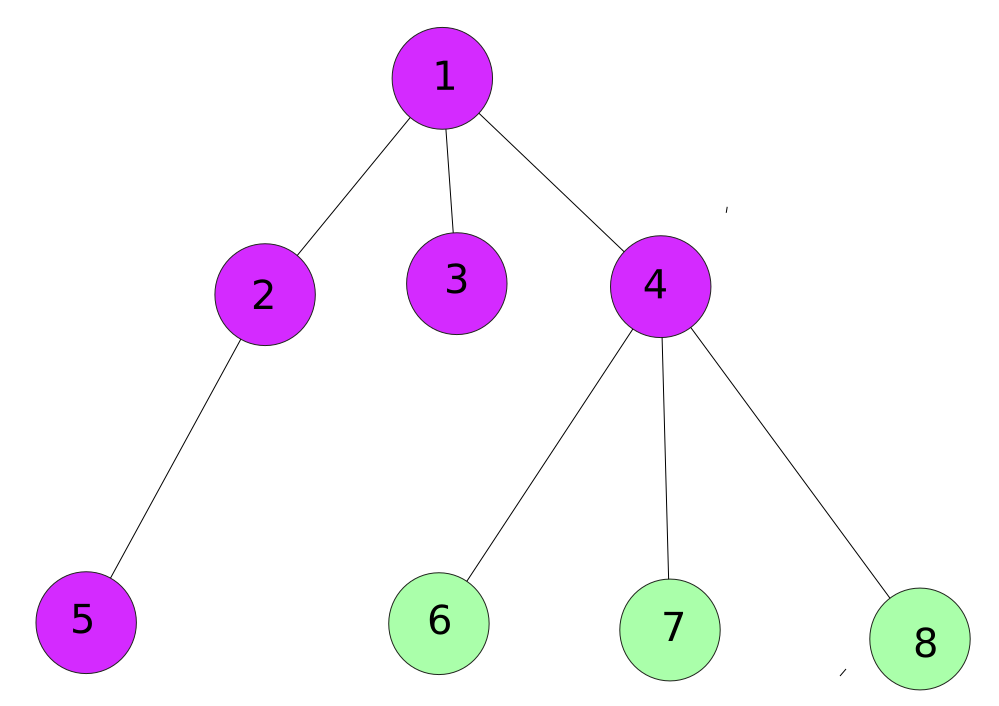 Since there are no children of 3 we move to the next child which is 4.
Since there are no children of 3 we move to the next child which is 4.
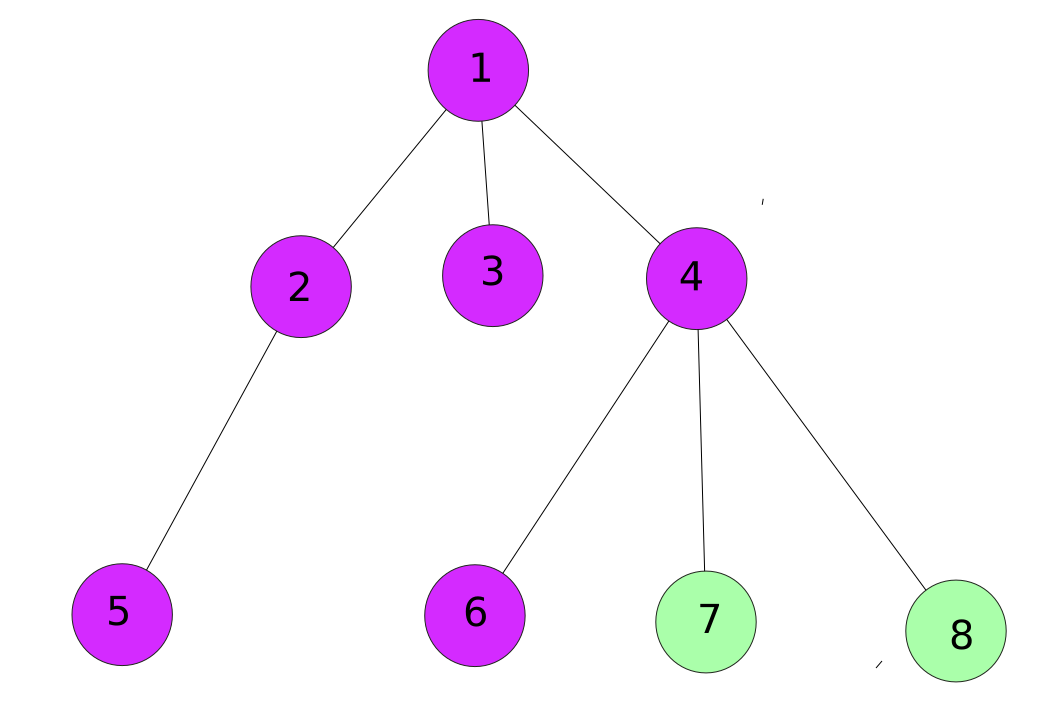 then we move to first child of 4 That is node 6.
then we move to first child of 4 That is node 6.
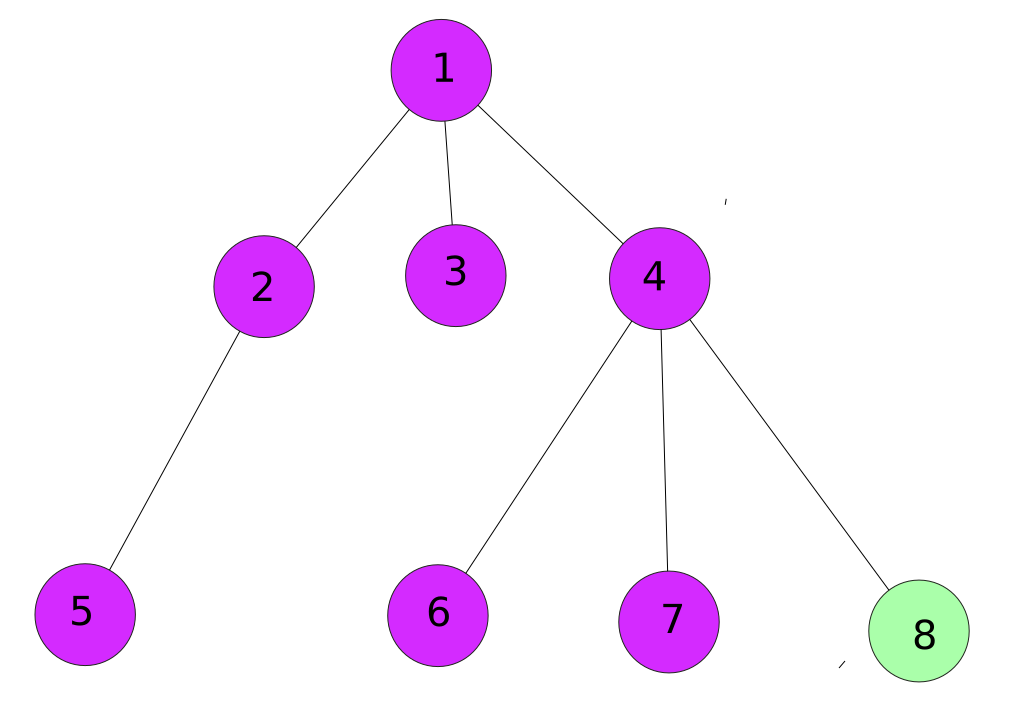 Then we complete the node 7.
Then we complete the node 7.
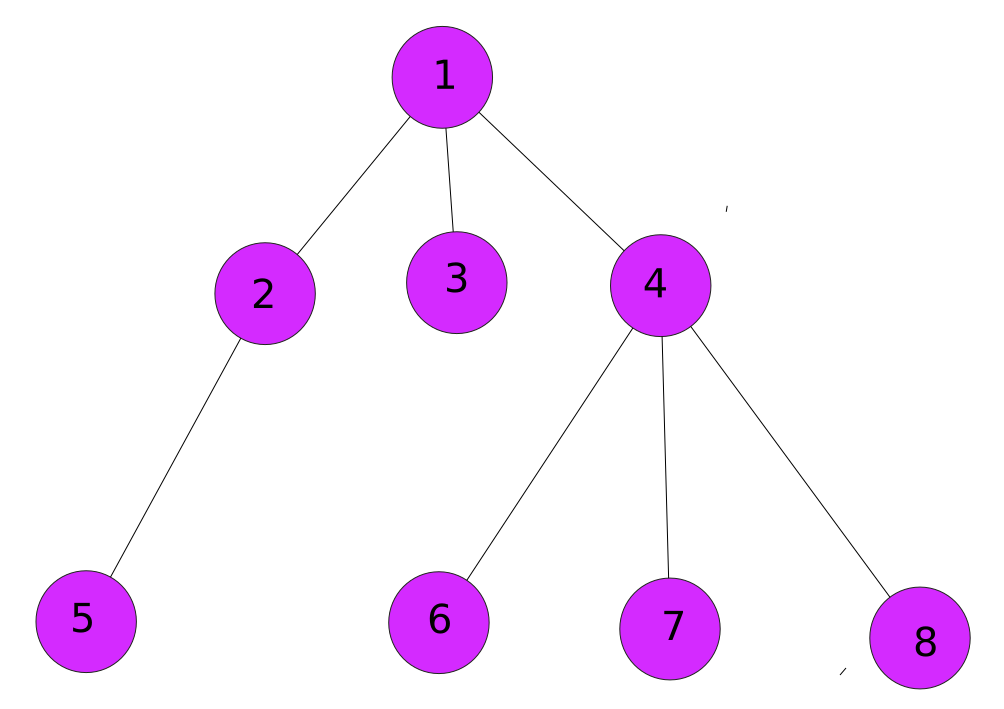 and we finish it with node 8.
and we finish it with node 8.
Other algorithms
Refer the following link Common Tree Algorithms - I Common Tree Algorithms - II
Lets Solve a Problem
The problem statement is in the link below - XOR-Tree
So the problem states that on flipping the value of a node all the subsequent alternate children also get flipped. We need to change it in such a way that we get the desired values of all nodes. First thing to notice is flipping a node only affects the node itself and any of its children. So we need to start from top and follow a greedy approach by flipping a node value wherever it is required.
Second thing to be noticed is that we will use a DFS with some modification.
Now, coming to the main catch of the problem, suppose you already flipped a node ,all subsequent alternate nodes also get flipped, now suppose a child of a child of a node who is flipped had an opposite value in the target value, then we already have flippped it but we have not monitored or taken care of , of it. The case can be of a even deeper node and we can’t manually update that everytime because it will costly.
So what we can do? We can maintain three extra parameters that is number of flips so far on even and odd positions and another parameter as the current level paramter. Below is the code for modified dfs with the main() function for the input. Put on the thinking caps and try to figure out the logic behind the even,odd and level parameters and the if-else conditions,
vector<int>init,goal;
vector<int>flip;
void dfs(vector<vector<int>>&g,vector<int>&visited,int root,int even,int odd,int level)
{
if(init[root] == goal[root];
{
if(level%2 == 0)
{
if(even%2)
{
flip.push_back(root+1);
even++;
}
}
else
{
if(odd%2)
{
flip.push_back(root+1);
odd++;
}
}
visited[root] = 1;
for(auto nodes : g[root])
{
if(!visited[nodes])
dfs(g,visited,nodes,even,odd,level+1);
}
}
else
{
if(level%2 == 0)
{
if(even%2 == 0)
{
flip.push_back(root+1);
even++;
}
}
else
{
if(odd%2 == 0)
{
flip.push_back(root+1);
odd++;
}
}
visited[root] = 1;
for(auto nodes : g[root])
{
if(!visited[nodes])
dfs(g,visited,nodes,even,odd,level+1);
}
}
}
int main()
{
int t = 1;
while(t--)
{
int n;
cin>>n;
vector<vector<int>>g(n,vector<int>());
for(int i = 1;i<n;i++)
{
int u,v;
cin>>u>>v;
u--;v--;
g[u].push_back(v);
g[v].push_back(u);
}
for(int i = 0;i<n;i++)
{
int val;
cin>>val;
init.push_back(val);
}
for(int i = 0;i<n;i++)
{
int val;
cin>>val;
goal.push_back(val);
}
vector<int>visited(n);
dfs(g,visited,0,0,0,0);
cout<<flip.size()<<"\n";
for(auto flipper : flip)
{
cout<<flipper<<"\n";
}
}
return 0;
}
Thanks for reading ;) .
