Neural Style Transfer
Neural Style Transfer is the problem of applying the style of an image/painting onto a content image. For Humans the process of painting is seamless. In this blog we will step by step include components into style transfer model, in order to improve the results, first look into the loss functions which capture style representations, next feed-forward networks which produce styled images given style and content image, Then we will look into style embedding and how this can be used to produce new styled images even for unseen paintings.
Style and Content loss
As loss function captures the objective of a model, we shall first look into style and content loss functions. When training CNN model for image classification, each layer captures certain features of the input image .the lower layers capture low-level information whereas the higher-level layers capture the high-level content in terms of objects and their arrangement in the input image but do not constrain the exact pixel values. So we can say that the activations of higher layers contain information about the content of an input image. Gram matrix of a layer contains the dot product between different channel activations of a given layer this contains information on correlation of features extracted by different channels of a layer. The gram matrix contains the correlation between activations of different channels of a layer, this is similar to painting where we see a pattern or certain colour play, So we use gram matrix of lower layers as style representation of an input image.
Style Representation
\[\Large G_{ij}^l = \sum_k F_{ik}^l . F_{jk}^l\]Here Gijl is the ijth entry in the gram matrix of Layer l. Fil is the activations of ith channel in lth layer. We use the pre trained VGG16 Network for activations

We consider the content representation of the content image to bo the target for content loss and we consider the style representation of style image as a target for style loss.
Content Loss given Pl is target content activation of layer l:
\[\Large \mathcal{L}_{content}(\vec{p},\vec{x},l) = \frac{1}{2}.\sum_{i,j}(P_{ij}^l-F_{ij}^l)^2\]Style loss given Al is target style representationof layer l:
\[\Large E_l=\sum_{i,j}(A_{i,j}^l-G_{i,j}^l)^2\\ \mathcal{L}_{style}(\vec{a},\vec{x})=\sum_{l=0}^L(w_l.E_l)\]Here wl is the weight per layer, the weight decreases from lower layers to higher layers
Total Loss given content representation \(\Large \vec{p}\), style representation \(\Large \vec{a}\), styled image representation \(\Large \vec{x}\):
\(\Large \mathcal{L}_{total} = \alpha.\mathcal{L}_{content}(\vec{p},\vec{x})+\beta.\mathcal{L}_{style}(\vec{a},\vec{x})\) Here \(\large \alpha\) and \(\Large \beta\) are weights for content and style loss.
The brute force method to generate the styled image is to take a noise image and calculate its loss from pre-trained image classifier given style and content image and then apply gradient descent on individual pixels of noise image and repeating this process iteratively till we convert noise image to styled image. This method consumes a lot of time and there are no learned parameters.
Image Transformation Network
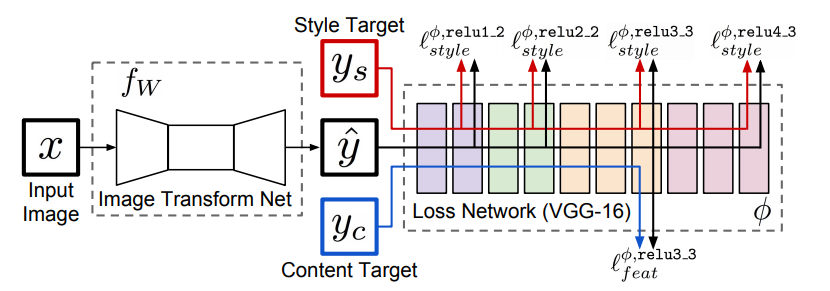
Here the image transformation network learns to map the content image to the style of the painting image, using this network we can generate images of a particular style. The image transformation network consists of Residual blocks and non-residual convolution layers, for upsampling it uses fractional strided convolution. Batch normalisation takes place after every convolution layer, The output layer uses tanh activation to provide output in the range [0-255] The loss network is used to calculate the respective content and style loss given the style and content image. Using gradient dissent the model is trained in order to decrease the loss. The drawback of this is it can be used to generate the style of a single painting and not multiple paintings, so training new weights for new painting style is not practically feasible as it takes a lot of memory. In the conditional instance normalisation, we will make a few changes to this image transformation network using which we can generalise or use the same weights for multiple styles.
Conditional Instance Normalisation
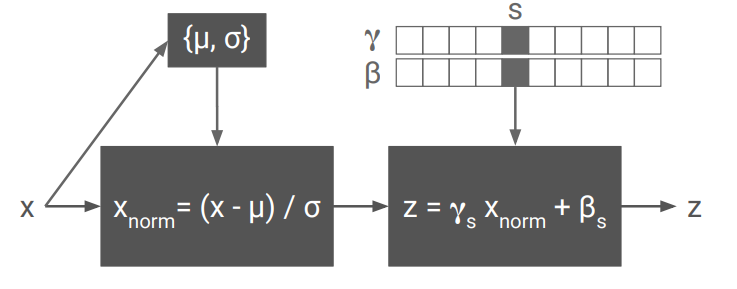
We can see that many paintings share some common features like brush strokes etc, conditional instance normalisation helps us to encode style into an embedding and a common image transformation network for multiple styles. To understand about instance normalisation please look at this blog link. We see in this paper that instance normalisation is better than batch normalisation in image transformation network. For using a single image transformation network for multiple styles, we see the work in this paper, where they found a surprising fact about role of normalisation in transformation network, where scaling and shifting of the instance normalized activations can be used to produce different styles. For each style, the activations of instances normalised layer are scaled and shifted differently and these scaling and shifting parameters represent the style as an embedding in space, we can use this property and can find embedding of different styles and during production for different styles, we can just change these shifting and scaling parameters in order to produce different styles, which majority of the weights remaining the same.
\[\Large z = \gamma_s.(\frac{x-\mu}{\sigma}) + \beta_s\]So for each style we can train γs and βs which represents the particular style and can be replaced if we wanted different style. this decreasing the cost of memory.
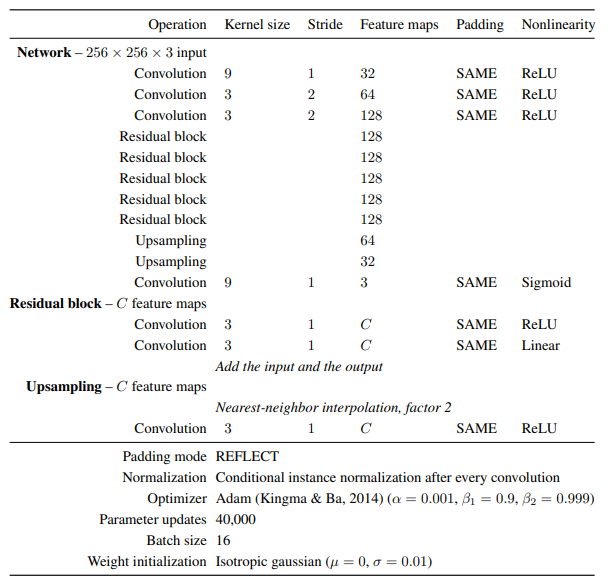
The image transformation network details are given in this paper For implementing multi-style transfer;
The main drawback of this is we can not generate a styled image for an unseen style.
Style Prediction Network
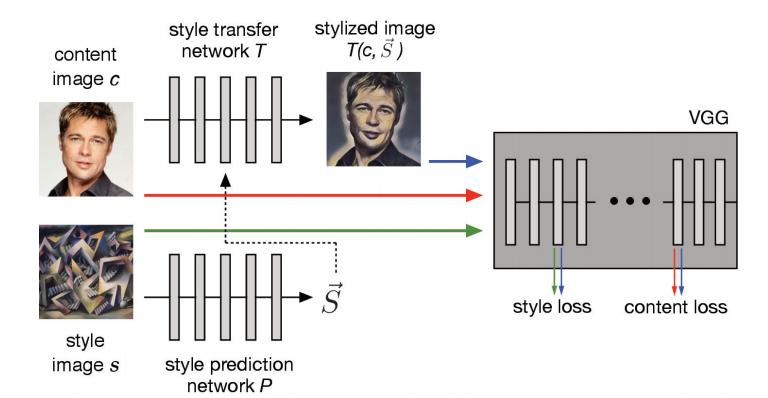
The style prediction network takes the style image as input and produces the style embedding(shift and scale parameters) for the particular style. This helps us to generalise to unseen styles. The style prediction network generates the shift βs and scaling parameters γs which are described in conditional instance normalisation part. On plotting the embedding of style image we can see that similar styles are close to one another. This model is time,space-efficient and also it can generate stylized images for unseen style, this model can be deployed on mobile and desktop apps and would produce amazing results. For more information refer to this paper
References
- A Neural Algorithm of Artistic Style
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- Instance Normalization: The Missing Ingredient for Fast Stylization
- A Learned Representation For Artistic Style
- Normalization Techniques in Deep Neural Networks
- Exploring the structure of a real-time, arbitrary neural artistic stylization network
