Prerequisites
Trees, DFS, Min-heaps
Introduction
In this era of the internet, we constantly need to send and receive files. It is in our best interest that these files are as small as possible so that we can save on bandwidth and network usage. Hence, it is important to compress or encode files to minimize their transmission size.
For text files, one of the most popular compression algorithms is Huffman encoding. In Huffman encoding, each character is assigned a variable-length code, and this assignment is sent as a header file. The codes are in binary, and they are prefix codes, i.e., the code of one character is never the prefix for the code of another character. The most frequent character has the shortest code, and the least frequent has the longest code. The difficulty is in assigning codes to these characters, which is discussed below.
Huffman encoding algorithm and Huffman tree
The first part of the Huffman encoding algorithm is building a Huffman tree from the given characters. From the Huffman tree, we can give codes to the characters which will be used for the compression.
We will use the below line of text as the source string:
acbaabbacaaacaccbacaaabcbccaccacaacaacabbabcacabacaacbaaaacaabbacaaaaabaabbaaaabbbccacaaccbaaaa
The following are the steps to make a Huffman tree:
For each unique character in the source text:
Make a leaf node in the tree storing the frequency of the character
Build a min-heap of nodes, which compares based on the frequency of the nodes
while the size of the head is greater than one:
Extract 2 minimum nodes from the heap
Create a node with frequency as sum of frequencies of extracted nodes
Set extracted nodes as left and right children of newly created node
Insert the new node in the min-heap
After these steps, the Huffman tree is complete, and the last node is treated as the root of the tree.
Consider the character frequencies in the example:
a: 50
b: 20
c: 25
- Three leaf nodes are created, one for each character.
- A min-heap is created with these nodes.
Min-heap state: 20 25 50
- 20 (b) and 25 (c) are extracted from the min-heap. A new node with value 45 is created, the two nodes are added as its children and it is placed in the heap.
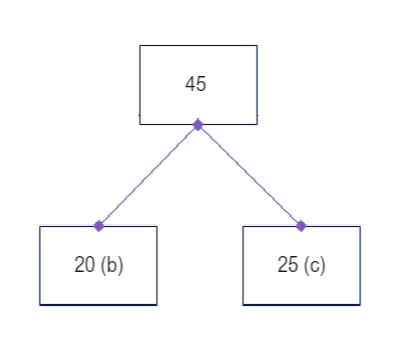
Min-heap state: 45 50
- 45 and 50 (a) are extracted from the min-heap. A new node with value 95 is created, the two nodes are added as its children and it is placed in the heap.
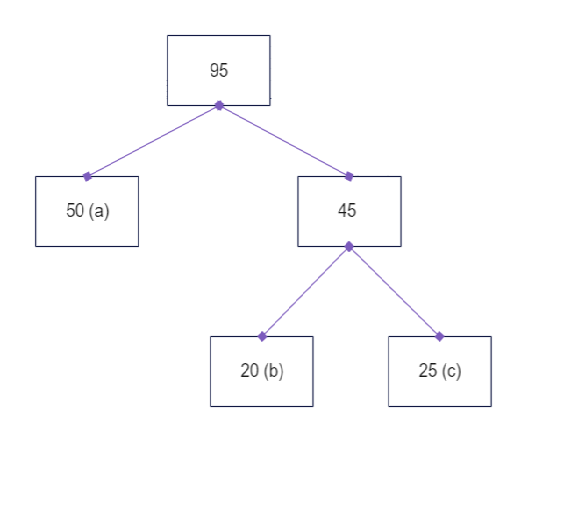 Min-heap state: 95
Min-heap state: 95
- The min-heap has only one element, and the Huffman tree is complete.
The second part, as mentioned earlier, is to assign codes based on the Huffman tree. To do so, we do the following:
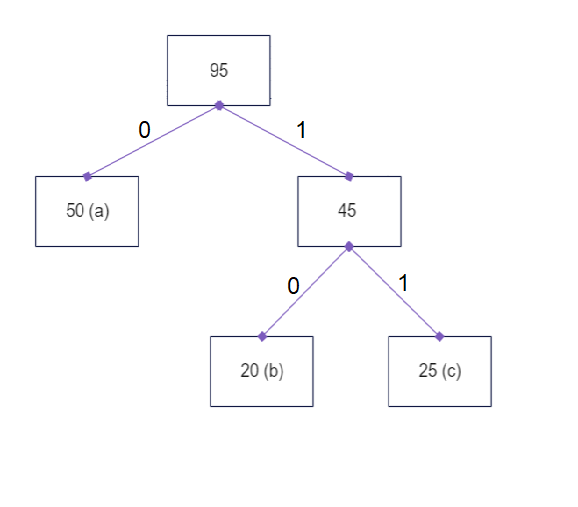
Start at the root node, and maintain a binary string (initially empty)
Perform DFS on the tree starting from the root
If left child is being visited:
0 is appended to the binary string
If right child is being visited:
1 is appended to the binary string
If DFS is completed on a node and the node is being exited:
The binary string’s last character is popped
If we reach a leaf node (associated with a character):
The Huffman code of that character is the binary string
In the previous example, if we do the above, we end up with the following assignment:
a: 0
b: 10
c: 11
To get an idea of why this method gives an optimal code, we have to consider the original objectives listed below:
- The lengths of character codes are dynamic, and more frequent characters get shorter codes.
- The code of one character is never the prefix of the code of another character.
It should be clear from the algorithm that the Huffman tree will have more frequent characters closer to the root because higher frequency characters are extracted later in the algorithm. The distance of a character node from the root(in terms of edges) is the length of the character code. Hence, more frequent characters will have shorter codes and the first objective is achieved.
In the Huffman tree, the exact character code depends on the path from the root to the node with the character. If the code of some character A has to be the prefix of some other character B, A will have to lie on the path from the root to B. Since characters are always stored in a leaf node, the path from the root to character B cannot contain the node for character A. Hence, the prefix code condition is achieved.
Note
As the reader may have noticed, there exists an edge case to this algorithm, which is if the text file contains only 1 character. If the above algorithm is followed, the character ends up with no binary code.
This edge case has to be dealt with in the decoding program only since the header file containing the frequencies of the characters will make it clear that the file consists of a single character repeated several times. The header file is discussed in more detail below.
The final encoding
Now that we have the codes for each character, we can start the encoding to reduce the file size. The procedure is simple. We replace each character with its code to get a binary string for the entire file. Since the code is a prefix code, there can be no ambiguity in the translation. After encoding the example string, we get:
01110001010011000110111110011000101110111101111011001100110101001011011010011001110000011001010011000001000101000001010101111011001111100000
This binary string has to be stored in a binary file to achieve compression, i.e., the inner bits of the file have to correspond to the binary string. To do so, the simplest method is to divide the string into parts of 8 bits and store each 8 bit part in a single character which is written to the compressed file. After this, the 140 character binary string can be written in 18 bytes of memory, compared to the 95 bytes of the original text.
This solution, however, is not complete. That is because the last character to be generated this way need not contain all 8 bits, but the translation program, while decoding, would not be able to tell how many bits to use.
One simple solution to this is to include End of File (EOF) as a character in the Huffman encoding algorithm. When the decoding program reads EOF, it can immediately terminate translation, and hence garbage bits would not be read.
Finally, just the binary file is not sufficient for translation. We need another file (often called the header file) to tell the decoding program about the character codes. The character codes can be given directly, or to further optimize space, the characters and their frequencies can be given. This can be achieved by storing the characters and frequencies in a suitable data structure and writing the entire structure to the header file. The decoding program can then retrieve the frequencies and run the same Huffman algorithm to generate character codes.
In the given example, there are 3 characters whose frequencies have to be given in the header file. If we optimize space properly, the header file should contain 3 characters and 3 ints, which is ~15 bytes. Hence the overall size will be 15 + 19 = 34 bytes, which is much smaller than the initial size of 95 bytes.
Hence our objective of text file compression is complete.
Conclusion
Huffman Algorithm is a popular way of compressing text files. We have discussed the algorithm, the problems faced in its implementation for file compression as well as possible solutions. With this blog as a reference, the reader should be able to write their own program for text file compression.
References
