Introduction
A disjoint-set data structure, also called a union–find data structure or merge–find set, is a data structure that stores a collection of disjoint (non-overlapping) sets. Equivalently, it stores a partition of a set into disjoint subsets.
Capabilities
This data structure provides the following capabilities. We are given several elements, each of which is a separate set. A DSU(Disjoint set union) will have an operation to combine any two sets, and it will be able to tell in which set a specific element is. The classical version also introduces a third operation, it can create a set from a new element.
Basic Interface
Thus the basic interface of this data structure consists of only three operations:
- make_set(v)- creates a new set consisting of the new element v
- union_sets(a, b) - merges the two specified sets (the set in which the element a is located, and the set in which the element b is located)
- find_set(v) - returns the representative (also called leader/parent) of the set that contains the elementv. This representative is an element of its corresponding set. It is selected in each set by the data structure itself (and can change over time, namely after union_sets calls). This representative can be used to check if two elements are part of the same set or not. a and b are exactly in the same set, if find_set(a) == find_set(b). Otherwise they are in different sets.
How it works
We will store the sets in the form of trees: each tree will correspond to one set. And the root of the tree will be the representative/leader of the set.
In the beginning, every element starts as a single set, therefore each vertex is its own tree.
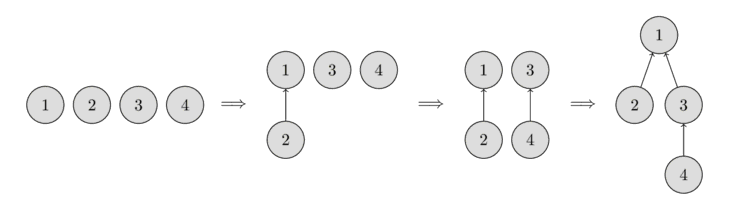
Then we combine the set containing the element 1 and the set containing the element 2. Then we combine the set containing the element 3 and the set containing the element 4. And in the last step, we combine the set containing the element 1 and the set containing the element 3.
For the implementation this means that we will have to maintain an array parent that stores a reference to its immediate ancestor in the tree.
Implementation
As I said, all the information about the sets of elements will be kept in an array parent.
To create a new set (operation make_set(v)), we simply create a tree with root in the vertex v, meaning that it is its own ancestor.
To combine two sets (operation union_sets(a, b)), we first find the representative of the set in which a is located, and the representative of the set in which b is located. If the representatives are identical, that we have nothing to do, the sets are already merged. Otherwise, we can simply specify that one of the representatives is the parent of the other representative - thereby combining the two trees.
Finally the implementation of the find representative function (operation find_set(v)): we simply climb the ancestors of the vertex v until we reach the root, i.e. a vertex such that the reference to the ancestor leads to itself. This operation is easily implemented recursively. Here is the implementation -
void make_set(int v) {
parent[v] = v;
}
int find_set(int v) {
if (v == parent[v])
return v;
return find_set(parent[v]);
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b)
parent[b] = a;
}
The time complexity of this algorithm is O(N) where N is the size of the set of elements.
Improving the efficiency of the algorithm
Path Compression
Path compression is useful for speeding up the find_set function.
If we call find_set(v) for some vertex v, we actually find the representative p for all vertices that we visit on the path between v and the actual representative p. The trick is to make the paths for all those nodes shorter, by setting the parent of each visited vertex directly to p. Here is the implementation -
int find_set(int v) {
if (v == parent[v])
return v;
return parent[v] = find_set(parent[v]);
}
The simple implementation does what was intended: first find the representative of the set (root vertex), and then in the process of stack unwinding the visited nodes are attached directly to the representative. The complexity has been reduced to O(NlogN).
Union by Rank
Think about what happens when we join the larger tree to the smaller tree while merging the two sets. Clearly this can lead to trees with chain length of O(N). So if we always join the smaller tree to the larger one, we can significantly reduce the time complexity.
In this approach, we use the size of the tree as the rank and we join the tree with lower rank to the one with the higher rank. Here is the implementation -
void make_set(int v) {
parent[v] = v;
rank[v] = 1;
}
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (rank[a] < rank[b])
swap(a, b);
parent[b] = a;
rank[a] += rank[b];
}
}
Time Complexity
If we combine the two optimisation techniques that we discussed, the time complexity comes out to be O(α(n)), where α(n) is the inverse Ackermann function, which grows very slowly. In fact it grows so slowly, that it doesn’t exceed 4 for all reasonable n. So we can say that we will reach nearly constant time queries. This is one of the reasons why a disjoint-set is so powerful.
Applications
Connected Components in a graph
This is one of the obvious applications of DSU.
Formally the problem is defined in the following way: Initially we have an empty graph. We have to add vertices and undirected edges, and answer queries of the form (a,b) - “are the vertices a and b in the same connected component of the graph?”
Here we can directly apply the data structure, and get a solution that handles an addition of a vertex or an edge and a query in nearly constant time on average.
This application is quite important, because nearly the same problem appears in Kruskal’s algorithm for minimum spanning tree and DSU helps in reducing it’s time complexity.
Job Sequencing problem
Given a set of n jobs where each job i has a deadline d_i >= 1 and profit p_i >= 0. Only one job can be scheduled at a time. Each job takes 1 unit of time to complete. We earn the profit if and only if the job is completed by its deadline. The task is to find the subset of jobs that maximizes profit.
Note : If you try to solve this greedily the time complexity will be O(n^2) but DSU makes it much faster.
All time slots are individual sets initially. We first find the maximum deadline of all jobs. Let the max deadline be m. We create m+1 individual sets. If a job is assigned a time slot of t where t => 0, then the job is scheduled during [t-1, t]. So a set with value X represents the time slot [X-1, X].
We need to keep track of the greatest time slot available which can be allotted to a given job having deadline. We use the parent array of Disjoint Set Data structures for this purpose. The root of the tree is always the latest available slot. If for a deadline d, there is no slot available, then root would be 0.
Conclusion
We can clearly say that DSU are one of the most efficient data structures and are really helpful for various algorithms. They are efficient and use small amount of memory. I hope that this article will help you quickly familiarise yourself with DSU as it can help you in solving various problems quickly and efficiently.
References and further reading
